Brian's Waste of Time
I dropped in on Scoble's geek dinner thing down the street. I admit I had an agenda -- I wanted to catch up with Avi Bryant whom I have wanted to meet for a while as I think he does very interesting hacking, and as Dabble looks really cool. He demonstrated it for the Flock guys and myself and it makes gmail look like SquirrelMail in terms web applications compared to web sites. Very nice! I particularly like the hands-on data mucking aspect.
Along the way met at least one, possible more, of the Flock folks, who are all of a couple blocks away. Nice guy(s). Flock is actually much slicker than I had thought, too. They keep pushing it as a social bookmarking thing, which is not all that exciting to me. It is way more. I'm glad Andy showed me around the corners of it some. Need to break out the Javascript!
FInally, I may have conned Avi into giving me a Squeak tutorial. Apparently he suffered from the same "this cannot be serious" reaction I keep having to Squeak (and even Visual Works, though that is less glaringly obnoxious). Apparently when someone who is good shows you around things start clicking. I'll believe it after seeing what he's done. I would not want to write that in any kind of model 2 framework, period.
Fun time, hope to see ya'll again before too long!
0 writebacks [/tech] permanent link
Thu, 29 Dec 2005
In a great example of convergence, I have been bumping into FastCGI
and Apache 2.x all over the place lately. I was able to beg Paul Querna (congrats on
being voted in as a member!) into giving me a module writing
tutorial at ApacheCon (where the previously mentioned
mod_wombat was born) specifically with the intention of
putting my money where my mouth is helping with Apache 2 and FastCGI
(or Zed Shaw's new SCGI module).
It turns out Paul has beaten me to the punch -- he and Garrett Rooney already have
work going on
mod_proxy_fcgi in httpd trunk. This should provide
remote fcgi instances, all the goodness from
mod_proxy_balancer, and places FastCGI in the core of
the web server instead of as a third party module! Awesome! It's
being worked on in the trunk, but I offered (the email is still in
my outbox as I am offline at the moment) to help maintain a 2.2
branch as I'd like to be able to use this Real Soon Now. Of course I
have no C or httpd credentials, but that is what patches are
for. Hopefully this can be made to work. I used to hack
C/C++... a decade ago =) Scrape the rust off and we'll see how it
goes.
Along the way I learned that Nick Kew had patched the
existing mod_fcgi to work against HTTPD 2.2. The catch
is there has been a lot of FUD about mod_fcgi and
Apache 2.x, but no one I know has been able to cite exactly what the
problem is, just a nebulous "there are issues."
So, big request, if you have had issues with mod_fcgi and Apache 2, please email me ( brianm@apache.org ) or the FastCGI Developers list and I promise to try and get things fixed even if I have to fix it myself (which would not be real-soon-now as my C is pretty derned tootin rusty, unfortunately, but it'd happen!) but I get the feeling a lot of the httpd hackers would like to lay this to rest =)
4 writebacks [/src] permanent link
Fri, 23 Dec 2005
Rails Presentations from ApacheCon '05
Copies of my Rails presentation from ApacheCon US '05 are up (finally). My apologies for having the wrong one on the CD from the conference. I think the CD makes up for it though by including a presentation on Drools under the Rails talk demonstration, along with the older version (and probably more useful to a non-live audience) of the Rails slides.
This was a fun, though somewhat scary, talk to give. It was fun because the subject is dear to my heart (I do believe that Ruby (and Rails)) is better for a lot (not all) of the development being done right now). It was scary because Rails is such a hot topic that it lead to a really big audience and probably high expectations. Then Craig and Craig started asking questions. Craig and Craig being rather eminent people in their respective fields, those fields being object/relational mapping and web frameworks respectively (rather relevant to Rails).
Feedback aftward indicated that the presentation was useful and enjoyable though. Phew!
If I can figure out a way to post the presentation complete with the undead (not live, but it looks live) code I will. Right now that would mean posting a 70 meg keynote file though and I don't want to inflict that on my bandwidth consumption =(
ps: an interesting conversation occured right before the talk. It was interesting for two reasons. First, the guy I was talking to (at ApacheCon) responds to an @microsoft.com email address. Second, he was looking for someone to give a talk about Rails (not for Microsoft directly, though).
0 writebacks [/src/ruby] permanent link
Sat, 17 Dec 2005
HOWTO: Import RSA Private Key and x.509 Cert into Java Keystore
In all seriousness, the instructions there for Jetty generate a keystore usable anywhere, not just for Jetty. I've always thought that Jetty rocks as a servlet container, turns out it is an awesome key and certificate management tool too!
0 writebacks [/src/java] permanent link
Thu, 15 Dec 2005
ApacheCon US 2k5: Heading Home
Sitting in the San Diego airport waiting for a delayed flight =( I even got here early to be safe, spend almost no time in security, and now... wait. That said, is a nice chance to unwind. I have been running on nerves most of the conference for various reasons. Really, I won't get to unwind until (hopefully) Saturday, but this is a wee bit of a teensy breather.
Was a great conference, ApacheCon is still my favorite, bar none =) I wound up doing lots of DB PMC business, which was actually good as it was face to face instead of email to email. Got lots of hacking done as well, but most of it was day job stuff -- a few non-day-job things deserve note though.
Paul Querna gave me a great tutorial on writing apache modules. It
has been... a long time (a decade maybe?) since I have hacked any C,
and really it was much more C++ than C even then. So, in between
writing this and taking breaks from writing I am continueing to hack
at mod_wombat, which is the most r0xx0ring apache
module yet found, it, er, well, it prints out the wombat's name and
age! Woots!
Actually, I really like the module system's design, it makes lots of
sense and is straightforward (as straightforward as C gets for a
professed ruby hacker) to work in. I also like pulling 1100+
requests per second on my powerbook. Expect more
mod_wombat hackery to come!
Trustin Lee's tutorial on MINA (somewhere in the apache directory project, no
internet to get the correct link) which is a wonderful looking
framework for implementing network protocols. Really slick -- you
basically provide a codec and it does the select magic
(or however NIO does it on your platform) to slam app level
frames/packets/whatevers at you. Really looks like a snap. Alex says
it has no external deps, in which case... WOOT!
Julian Cash (google him) was at the conference making photos. He is brilliant. Go find his site (supersnail.[something]) and look over his work.
Lots of exciting Derby announcements. Ted Leung (google again, he'll be on top) blogged one of the most exciting derby things -- Francois [argh, cannot remember his family name] has written an Ajax client for Derby. Yep. Woot!
Caught up with bunches of people I love catching up with and met a passel of people I hadn't yet had the opportunity too. Apache and ApacheCon rock.
1 writebacks [/src/apache] permanent link
Sat, 10 Dec 2005Got to hotel, Torsten shows up in line, then Alex, then Leo =)
0 writebacks [/src/apache] permanent link
Thu, 08 Dec 2005From "Ruby, python, perl, java can't really compete as languages" all the way to night of the living python in... 6 days!
0 writebacks [/src] permanent link
Mon, 05 Dec 2005This is brilliant:

Note that the image has been made available under the Creative Commons Share-Alike, Non-commercial license, which means that this article is also under those terms, not my normal more nebulous terms.
0 writebacks [/tech] permanent link
Last night, Mike suggested I might enjoy this "one day confernce kind of thing" at SRI today, BrainJams. Unfortunate name, but interesting enough looking as I needed a change of pace and some more socializing =)
It was fun. Basically, it ran as an extended brainstorming session. Lots of creative people who were into ideas jamming (the name was appropriate, though still, I believe, unfortunate) and springboarding on each others' ideas. Topics ranged all over the map, with many interesting conversations and people.
Rather than rehash it in digest form, I'll just spew some of the fun notions that crossed my mind while there:
- smiles per hour
- simulating privacy by spamming lies into the information space
- conspiracy theories as externalized business think tank
- web 2.0 as technophile social movement
- food is a catalyst for community building
- ubiquitous lack of privacy (complete transparency) and idealized society (no behavior outside one standard deviation from the norm in the control society) would be mutually sufficient and mutually causal (and probably a deeply scary distopia)
- group decisions on the internet generally reduce to everyone who disagrees with the loudest people leaving until there is concensus between those who remain
- there is a deep unmet need for greater physical community amongst internet-oriented geeks
- regardless of the societal norm, and hence laws, technological possibility will outpace them and define new expectations which will become legal once the majority is used to them (this means an eventual total lack of the current conceptualization of privacy)
- courtesy will replace privacy
- we need more old geeks to put us young geeks in our places when we step out of line
"Smiles per hour," is my favorite, the rest of the notions could wander away and I wouldn't be too sad. I'd feel a lasting loss at what I couldn't remember if I were to lose "smiles per hour."
2 writebacks [/tech] permanent link
Fri, 02 Dec 2005
<span class="snarky">
LtU links
to an interview
which dared to ask "Why Lisp?" to the Reddit founder. Brian (Reddit guy) has
an appropriate smug-lisp-weenie answer ("Ruby, python, perl, java
can't really compete as languages"), but I suggest something much more
likely -- because Paul Graham
was funding it.
</span>
2 writebacks [/src] permanent link
Geir made coffee shoot out my nose!
In a comment on the proposed Tuscany project, Geir said, "It reads like 'mubble wubble SOA woogie blah foo SOA fwink thoobie wk SOA boo SOA apooth SOA SOA ... SOA ... '"
Now, is he referring to the Tuscany proposal, or the TLA industry?
0 writebacks [/src] permanent link
Wed, 30 Nov 2005I saw Bruce's post about (the incredibly useful) pbcopy/pbpaste today. They rock! That said, they are not quite what I need a lot of times, so here are a couple quick tools I whipped together for ye shell bangers.
get and put : These are basically a clipboard for the shell. Get takes input from standard in and stashes it. It is like yank or copy in a gui. Put does the opposite, it takes whatever get stashed and spews it to standard out (paste). No biggie, but useful: (I inserted the blank lines in the output, for readability)
brianm@kite:~/src/activemq$ cat build.properties | get
brianm@kite:~/src/activemq$ cd ../wombatattack
brianm@kite:~/src/wombatattack$ put > activemq.properties
brianm@kite:~/src/activemq$ cd ../wombatdefense
brianm@kite:~/src/wombatdefense$ put > activemq.properties
Now, the more fun tools are push and pop which are like put and get except they operate on a stack =)
brianm@kite:~/src/jdbi$ for x in $(find . -name Test*.java); do echo $x | push; done
brianm@kite:~/src/jdbi$ pop
./src/test/org/skife/jdbi/TestSQLOperations.java
brianm@kite:~/src/jdbi$ pop
./src/test/org/skife/jdbi/TestScriptStuff.java
brianm@kite:~/src/jdbi$ pop
./src/test/org/skife/jdbi/TestRowMap.java
brianm@kite:~/src/jdbi$ pop --clear
The shocking part is that, as far as I know, these type of tools aren't part of the standard shell environment!
4 writebacks [/src/ruby] permanent link
Tue, 29 Nov 2005I wish I could remember the question Matz was asked, at RubyConf, which lead to him answering Babel-17. I believe it was something along the lines of "What are languages worth learning?" or "what are good things to read about language design?" Maybe it was just "Could you suggest some good airplane reading?"
Anyway, at his suggestion I read Delancey's novella. It is quite worth reading. Aside from any literary merit, it presents Chomsky's idea the Sapir-Whorf hypothesis, most widely popularized (as far as I know) by 1984's NewSpeak, that what you are capable of thinking is determined by your language, in a novel and worthwhile way.
Because of the context in which I read it, I immediately started thinking about about how the programming languages we use influence how we think. People talk about "thinking in Lisp" or "thinking in Java" not infrequently. Languages do change how you think about solving problems by making it easier, more natural, more difficult, clearer, or more succinct to express some ideas rather than others. I think this represents the real measure of whether one language is better than another language.
The reason for my believing that the natural means of expressing something in a language determines if it is better, or worse, than another language, is that some ways of thinking simply are more effective. The difficult to argue against (except in Kansas) example of this would be that solving problems via the scientific method works better than solving them via the million monkeys approach. Both are valid ways of addressing a problem, one almost always works better.
In most domains there is semantic model for the domain which maps to it better than alternate models, and a language can make it easier, or harder, to work within a given domain. Low level programming (the realm of talking to the hardware) is very difficult to conceptualize via anything but imperative programming, for instance. The fact of the matter is that you are changing values in registers and using the values there to determine future actions. This is the nature of imperitive programming. Good fit, go figure. At the same time, when modeling mathematical systems you think in terms of pure functions, and the idea of being able to change state is absurd.
I selected the previous examples because they appear, to me, to be self-evident and thus good illustrations of the point. In other realms it becomes much less clear where one mode of thought trumps another. These examples also illustrate that a given system of thought may not be universally better (though finding a place where million monkeys trumps the scientific method might be tough; if I had to, I'd probably start looking in Topeka).
For me, the mode of thought in ruby (or smalltalk, or slate, or io) simply works better than the dominant mode of thought in python (or java, or C++, or awk). Is it universal? I don't know. I have found, over the last three or four years (since I started using scheme and ruby) that I write ruby code in Java quite frequently. I have found that the "really good" code in C, Java, and even Bash, tends to look like scheme, which is generally most easily expressed (to my eyes and fingers) using ruby syntax.
Not sure if I have any strong conclusions, just fuel for thought.
3 writebacks [/src] permanent link
Sat, 19 Nov 2005Stephan Schwab talks about companies honoring your investment in skills. He pines that recruiters (and an implication about HR in general) don't respect skills learned on your own time.
Sadly, I think that it is a good observation that a lot of places don't respect anything you have done which doesn't look like it was done in an enterprise context. My view on this particular practice is somewhat mixed, though.
The first thing I think about is when I decided to quit teaching and go (back) into programmering. This was probably right after the bubble burst and the layoffs were going. My programmering skills were pretty rusty and I hit the same wall Stephan describes with every recruiter I talked to. It was quite frustrating. I sympathize with anyone in that position, to some degree.
Then a few things happened. First, I talked to engineers (sometimes with fancy titles) instead of recruiters at a couple places and landed a job at a small company which didn't use recruiters. Woot. Eventually I landed at another company which totally changed my view of software and economies, and I came around to seeing why open source really is a better way for a large chunk of software. That is a digression, however.
From there I have steadily moved in a different direction on my view of the "recruiter won't talk to me because my experience is [hobby|open source|user group|part time]". Really it was learning a little bit of economics (thank you Roy and Mike!) and changing my view of "work."
As far as I am concerned, every recruiter, HR person, hiring manager, or whatnot that feels this way is doing me a huge favor by weeding out a lot of motivated and smart people from their applicant pool. This has two direct effects, first it is an invisible damper on the company's capacity, second it enriches the candidate pool for companies I work for. Making your company easier to compete against is fantastic, as is making sure to not snatch up the most motivated candidates. That is my perspective from a business point of view.
From a purely personal point of view... well, I am colored by the fact that I have a reasonably good looking resume now. Most of the accomplishments that mean a lot, to me, on it relate to stuff I have done independently of my job description, however. Interestingly, my most recent work has grown mostly out of those things (hobby kind of stuff).
So, when confronted with this... places that eliminate you from consideration because you are self-taught are probably not good long-term prospects for you, though if you are not presently working you may not care about long term at the moment, so this is a bitter pill. More helpfully, maybe, look for places that don't recruit through technology check lists and resumes spammed from recruiters, it is more work on your part, but has a better success rate, I believe.
Oh yeah, on the "learned in user group" thing -- if you are active in the user group, tell people there you are looking for a new job. Smart companies recruit out of user groups, it is a self-selecting group of people who have proven at least a modicum of initiative and motivation.
0 writebacks [/tech] permanent link
Just added a pluggable script locator module to jDBI. The script locator is used when you use the handle to execute scripts, so by default you can do:
handle.script("scripts/create-tables.sql");
handle.script("com/example/classpath-scripts.sql");
handle.script("https://example.com/scripts/remote-script.sql");
Of course, you can also write your own implementation of
ScriptLocator (define one method) which locates script
some other way =)
I pushed two releases with this. The first is a fully backwards
compatible 1.3.3 release. The second is a 1.4.0 release which
exposes the methods for specifying the statement locator and handle
decorator on the IDBI interface (and is a 1.X upgrade
as others may have implemented the interface and this would break
their implementation).
1 writebacks [/src/java/jdbi] permanent link
Fri, 18 Nov 2005Devender demonstrated shelling out to SQL*Plus to run a script, figured I had to trackback with a jDBI example that doesn't have to shell out, just for alternatives (and because this is a common mechanism for me to construct test schema =)
Our script, with various comment styles (this was taken from the regression tests for jDBI, btw):
-- insert 3 lines
insert into something(id, name) values (1, 'one');
# line 2
insert into something (id, name) values (2, 'two');
// line 3
insert into something (id, name) values (3, 'three');
and our code to run the script:
public void testScriptExample() throws Exception
{
Handle h = DBI.open("jdbc:derby:testing");
assertEquals(0, h.query("select * from something").size());
h.script("src/test-etc/insert-script-with-comments.sql");
assertEquals(3, h.query("select * from something").size());
h.close();
}
Shelling out to SQL*Plus is always an option I guess =) This did remind me that I need to change jDBI to use a script locator mechanism analogous to its named statement locator, in case you want to store your scripts on a web server, in the database, in JNDI, or... wherever comes to mind. Guess 1.3.3 may be out soon!
1 writebacks [/src/java/jdbi] permanent link
Wed, 16 Nov 2005Just pushed a minor jDBI release (1.3.2) which adds better error reporting on exceptions (it is much easier to get to the underlying SQLException on malformed SQL now).
Have fun!
2 writebacks [/src/java/jdbi] permanent link
Today in Disaster History! Ah, the sweet smell of tax dollars at work =)
0 writebacks [/stuff] permanent link
Tue, 15 Nov 2005Best phrase I've heard in a long time, "safe music experience." It makes me think back to my mosh pit days, but no, oh no, they are talking about safety to play the cd you bought.
Sony BMG deeply regrets any inconvenience to our customers and remains committed to providing an enjoyable and safe music experience.
I love it, "safe music experience." I could say that all day. None of that dangerous music now, only the safe music. Padded rooms with piped in muzak. Ha! The safest music experience available right now is mp3's from your friends, go figure. You buy it legally and they install a rootkit for you. Not sure that is what Sony intended.
0 writebacks [/stuff] permanent link
Fri, 11 Nov 2005It is said (you never know when or by whom) that of the seven deadly sins, each of us knows the one that will do us in if we let it. Mine is arrogance, so I work hard at being humble and fail far too often. Therefore, when I see something like Speak Softly(via Seth) it resonates. If you have a moment, it might well be worth reading =)
0 writebacks [/stuff] permanent link
Okay, so this is like kicking a dog with three legs, but I cannot resist =) Apparently, Java is good enough. Michael has some very good points -- the biggest being that languages have become dominant in the past when they have ridden a new application paradigm. Java rode the move from client/server to... a different client/server with a web client backed by a gargantuan app server playing the same role as the mainframe used to, or as he points out, with the mainframe still right behind it.
Apparently Java is good enough -- specifically in the arena of web app development. I think he misses Java's real strength which is that there is a huge pool of mediocre developers available who can do good enough work when given tools indistinguishable from magic =) This is a huge benefit, which is not to be underestimated, and no, my tongue is not in my cheek when I say that, really. The productivity level achievable with IDEA (or Eclipse, or NetBeans) and Java for the Corporate Developer (Sun's marketing term for who they aim Java at, at least the one they say to people) is immense.
So, because we have tools which make the language irrelevant, is it really Java we care about? I think we need to stop calling ourselves Java Developers and start being honest about it, we are IDEA Developers, Eclipse Developers, or, to be completely honest, XMLSpy Developers.
You master your tool and can work wonders with it. I have macros,
er, I mean Live Templates, for probably a third or more of the code
I actually right. tnuo[tab], test[tab], set[tab], tear[tab],
xsde[tab], puts[tab], itar[tab], fore[tab], itli[tab],
etc[tab]. Nice. Now, consider for a second an alternate
approach. Consider a tool which made it really easy to make those
macros, by say, interpreting them at runtime. You'd have to pick
better combos than tnuo (throw new
UnsupportedOperationException("come back and implement
me!");) but funny how it works. Now, that could be kind of
handy. What if you can do the same thing for how the tool
works?
Sure, Java is good enough. So are two penny nails. Unless you are trying to eat ice cream. Then a spoon helps.
Ruby isn't going to replace Java. Java is a marketing term for Gnome. Ruby isn't a window manager. Well, er, it does play nicely them though, not too bad, actually. Sorry, back off the tangent. Ruby isn't going to replace Java like Java replaced C++. Java replaced VB (which is an awesome tool around a ... hey, wait a minute!).
Java is definately good enough. The key thing is for it to evolve to stay good enough. Will it? Well, the language is under the control of a committee of committees of people who dislike each other. Luckily, we aren't actually Java Developers, we are IDEA Developers, and IDEA is under the control of some very big-thinking Russians. I think us IDEA Developers have some potential, not sure about the Eclipse folks though, they have the whole open source thing going, but it seems like most of the control over Eclipse is by people who sell competition to it and use it as a testbed for new research ideas ;-) So it will either be an awesome amalgamation of cutting edge software engineering research and heart warming open source community goodness, or a bike shed. Overall, not bad. I think us IDEA and Eclipse, and even the NetBeans Programmers, have a future.
Seriously now, IDEA is a fantastic, er, language (?) when you have big complex systems with a significant number of developers. Static typing, good garbage collection, a good compiler, excellent code navigation, and medium-level performance for the actual runtime (note that performance != scalability). It has fantastic libraries via it's Java runtime system, and bindings to most every information system around. IDEA has legs.
I still prefer Ruby, personally, but I do more work in IDEA than I do in Ruby, so take that as you want.
Side not: Fortran still being used because it is "good enough" is bollocks. Fortran is still used because nothing is faster when you need hardcore number crunching. Part of this is the immense optimization that has gone into compilers, the very mature vector processing libraries, the harsh limitations in what you can actually describe in the language in order to help the compiler optimize the code better (us IDEA developers have complained about non-reentrant EJB's, how about non-reentrant *functions*) etc. Most scientists I have met (this is not a scientific survey, I don't know that many) prefer Perl. Go figure.
9 writebacks [/src/ruby] permanent link
Thu, 10 Nov 2005After seeing the cool stuff you could do with Alexa in the whole /. vs Digg thing, I kept plugging in different urls to compare. After the 8th I realized I needed to script it, so...
0 writebacks [/src] permanent link
Sun, 30 Oct 2005Autrijus is a joy to follow. Aside from being, apparently, a brilliant hacker, he is just amazingly ahead of the curve:
Indeed, if JavaScript2 does survive the standardization process, it is entirely possible that it may become the next Ruby... [day 239]
=D
0 writebacks [/src/ruby] permanent link
Tue, 25 Oct 2005Just go watch it. Very elegant solution to functional state. At least to the this PL layman.
0 writebacks [/src] permanent link
Mon, 24 Oct 2005
Blog Abuse: Looking for Housing near Palo Alto
Time to abuse the blog for personal help now =) Anyone out there with info on a reasonable two bedroom rental (or three, or two plus small office, etc) near Palo Alto (Redwood City to Mountain View seems to be the suggested commute range) which will accept two small, middle-aged dogs (both rescues, very sweet dogs! Bouncer and Bean) please drop me a note!
Thanks!
Back to the regularly scheduled geekery!
2 writebacks [/stuff] permanent link
Sat, 22 Oct 2005David Balmain has released Ferret unto the world. Ferret is one of the most requested libraries I have seen for ruby -- a native port (not a gcj and bindings!) of Lucene!
#!/usr/bin/env ruby
require 'rubygems'
require 'ferret'
require 'find'
include Ferret
# index = Index::Index.new(:path => '/tmp/ferret-test')
index = Index::Index.new(:default_field => 'content')
Find.find("/Users/brianm/blosxom/entries/src/") do |path|
if FileTest.file? path
File.open(path) do |file|
index.add_document :file => path,
:content => file.readlines
end
end
end
index.search_each("Lucene") do |doc, score|
puts index[doc]['file']
end
Yields:
brianm@kite:~$ ./ferret_test.rb
/Users/brianm/blosxom/entries/src/java/ojb/lucene-ojb.txt
/Users/brianm/blosxom/entries/src/ruby/#ferret.txt#
/Users/brianm/blosxom/entries/src/java/spring-lucene.txt
/Users/brianm/blosxom/entries/src/java/lucene-graphs.txt
/Users/brianm/blosxom/entries/src/ruby/gcj-osx.txt
/Users/brianm/blosxom/entries/src/ruby/codefest-grant.txt
/Users/brianm/blosxom/entries/src/reseach-solipsysm.txt
/Users/brianm/blosxom/entries/src/java/rails-for-strutters.txt
brianm@kite:~$
Yea! Now to get David Black to send him my grant...
0 writebacks [/src/ruby] permanent link
Tue, 18 Oct 2005PHP gets a lot of grief in Java and Ruby camps. That said, my question is whether this is fantastically powerful, or outright scary:
Java:
Object foo = Class.forName(actionName)
.newInstance();
String templateName = (String)Class.forName(actionName)
.getMethod(eventName, new Class[]{})
.invoke(foo, new Object[]{});
PHP
$foo = new $action_name();
$template_name = $foo->$event_name();
Hmmm
6 writebacks [/src/php] permanent link
Sun, 16 Oct 2005
Matz offered a number of options for lambda (anonymous function)
creation syntax during his keynote. Figure I can comment as some of
the thoughts are subtle. My gut reaction was to stick with
lambda but something itched. I think I figured it out,
but let's look at options.
f = lambda (x=5)
puts x
end
f = lambda (x=5) { puts x }
f = -> (x=5) { puts x }
f = (x=5) { puts x }
f = def (x=5)
puts x
end
The thing that bugged me about *all* of these is that the default
value for the parameter (x=5) looks like it is
being evaluated, not like a default value. This highlights, for
instance, a big difference between python and ruby, in python the
(x=5) is a statement, not an expression, and isn't the
default in that context. I dislike this about python.
Oddly enough, the syntax I like the least, f = -> (x=5) { puts
x } is probably the clearest for this as, visually, the arrow
looks like it pushes the parens into the function def, kind
of. Really, I want the params to be inside the block, I think, like
the current goal posts. One thing suggested by the audience was the
groovy method, f = { x=5 -> puts 5 }, which I quite
like, and Matz thought about, but dismissed as looking too much like
a hash ( { :x => 5 }, which it does, I agree =(
Blocks and anonymous functions will remain different, and I
certainly trust Matz on this, though I don't see the reasoning
personally =) If they are, then... maybe something block like is
good. Matz seems pretty set on having parens for the args outside of
the block, and I cannot say I disagree -- I just don't want the
confusion over whether (x=5) is an assignment in the
scope of the definition, or a default value in the scope of the
invocation (execution in aspectj terms).
Aside from that, fantastic presentations by Ryan Davis and Jim Weirich on cool ruby hacks in the afternoon, nice (and really interesting) case studies in the morning. I had the advantage of sitting next to one of the Io hackers (Brian Mitchell) most of the day, so picked his brain some, and played with Io. Interesting. Also installed Forth based on breakfast conversation. Have to muck with a language described as "kind of low level -- higher than assembly, lower than C" =) Slate still wins the "my brain hurts the most" award, so I doubt I'll stop focusing the majority my language muckery on it for the most part for a while =)
0 writebacks [/tech/rubyconf05] permanent link
Sat, 15 Oct 2005RubyConf has been fun, sleepy (got in late, woke up early, still on east coast time, but great fun =) Obie has been doing good presentation-by-presentation coverage, so I'll let him cover that. ;-)
SASADA Koichi is a fantastic presenter, and seeing how he is designing YARV was very interesting. I just wish I'd had more sleep. I need to dig through his presentation and try to remember some more C. I agree with him about block syntax in Ruby 2.0 =)
JRuby's progress is really interesting, the fact that it is being modeled on CISC and will be stackless via CPS is really cool. JRuby is definately alive and kicking.
On the flight and in some downtime today I've been beating on the ruby stomp client as well. Finally got a grip and started doing it right -- most of the old code has been thrown away and am doing it properly TDD this time. Basic client exists (it is that easy), but am still working on a better rubyomatic api.
0 writebacks [/tech/rubyconf05] permanent link
Fri, 14 Oct 2005To RubyConf and then to Palo Alto. Flight left almost on time, but is long =( Will give me time to rewite the ruby stomp client on the plane, I hope to release this weekend =)
1 writebacks [/tech/rubyconf05] permanent link
Tue, 04 Oct 2005Ning launched! Lots of folks have a lot to say about Ning if you haven't bumped across it yet, but I'll say my bit about what is most exciting technically to me =)
Ning is a public, schemafied, taggable, and free datastore for the web. The public content stuff is the exciting part -- any app can query across any app other app's data. You can fetch, say, every entity in the content repository which calls itself a Dog. You can only modify what you own, but you can see anyone elses. Oh, you can fetch them programmatically in Ning, or as an RSS feed, or via custom REST services, or... well, be imaginative. This is pretty cool. It is one of those things that if you think about for fifteen minutes you can come up with some really cool ideas, but... but... the best ideas are far over the horizon. This is enabling more than anything. Stuff no one has ever thought of will appear.
It's standards based, its open, you own everything you contribute (but license it under creative-commons attribution based licensing by default) -- both data and code. Cool stuff.
Oh, and I am totally into situated software, but that isn't a technical cool point, so will talk about that later =)
I could go on for a bit, I'm pretty excited by this. Of course, I am also moving to Palo Alto next week to work there, so I had better be!
Major kudos to the 24HL folks who have been working like crazy to get this out, I can't wait to join you.
4 writebacks [/tech] permanent link
Sat, 17 Sep 2005Sean E. Russell just announced SERStomp (working name) -- a super lightweight implementation of both the server and client sides of stomp. Woot!
Also, in stomp news, the plans for improving transaction support, explicit character encoding, and message ack modes are all at least touched on in the wiki. I'll update the protocol spec as I update the ActiveMQ implementation! Sean gets credit for anything intelligent in the character encoding, I get blamed for the stupid stuff =)
0 writebacks [/src/stomp] permanent link
Sun, 11 Sep 2005Tim Bray pointed out Microsoft's June 2005 financial statement. I am grateful to the president of a startup I worked at previously who taught me how to read these. This one is fascinating =)
The most interesting part, however, is just looking at the money around Microsoft's two (self reinforcing) monopolies. The first is Windows, of course. On the financial statement Windows translates to client (emphasis mine):
Client includes revenue from Windows XP Professional and Home, Media Center Edition, Tablet PC Edition, and other standard Windows operating systems. Client revenue growth is correlated with the growth of purchases of PCs from OEMs that preinstall versions of Windows operating systems because the OEM channel accounts for over 80% of total Client revenue.
That is nice, so what is interesting about the numbers? Well, we see a pretty nice top line revenue of $12.2 billion. The fun part of that is that the operating income (profit before taxes and interest) is a tidy $9.4 billion. It is awfully nice to pull a 77% operating margin (profit before taxes, hereafter referred to as "profit").
The other interesting part is what Tim was focusing on, the information worker lines (emphasis mine):
Information Worker consists of the Microsoft Office System of programs, servers, services and solutions designed to increase personal, team and organization productivity. Information Worker includes Microsoft Office, Microsoft Project, Microsoft Visio®, SharePoint® Portal Server CALs, and other information worker products including Microsoft LiveMeeting and OneNote®. Most revenue from this segment comes from licensing our Office System products.
This one has slightly slimmer profit margins, only 71.8% profit on $11 billion revenue.
Damn, it'd be nice to have my own monopoly.
Aside from the monopoly stuff, there are some plain interesting bits. Cash and short term investments are down $10 billion each from the same time last year. This presumably comes out of the one-time dividend payout they did in... June. Love seeing the $36 billion cash dividend payout. Yowzers!
Speaking of stock, they bought a healthy chunk back, about 8 billion shares, while issueing 3 billion. That means net loss of 5 billion MS shares floating around, leaving (I believe) 24 billion outstanding shares. That is a lot of buyback.
Their R&D spending is down about $1.6 billion, from $7.8 billion to $6.2 billion. Sales and marketing is up a bit (I love calling $270 million "a bit" =) to about $8.7 billion. So yeah, they do spend more on marketing than R&D, but they are a business and marketing is important. It is impressive how little of their topline revenue goes into marketing and sales, actually, at only about 22%.
It is of course nice to look at the non-monopoly business divisions as well. MSN is squeaking out a pretty respectable (20%) profit, with $2.2 billion in revenue and $405 million in profit. Servers have a very respectable margin as well, about 33% on $9.9 billion revenue. Both are very nice from a profit perspective, I'm too lazy to dig into more detail =) Business solutions, mobile, and entertainment all lost lots of money by normal standards, or small change compared to the Windows and Office profits, though the mysterious "other" lost the most, at almost $6 billion.
2 writebacks [/tech] permanent link
Fri, 09 Sep 2005Gotta love trying to make up sample rules when discussing possible rule authoring options in drools...
mich__: I'm trying to imagine a scenario where a rule would be part of two groups
mich__: Two distinct groups where only one rule needs to execute
brianm: here is an example
brianm: off top of head
brianm: you have a wombat, the wombat is on fire, and cannot see
brianm: when the wombat is on fire you have options to:
brianm: rule 1) stop drop and roll
brianm: rule 2) jump in a lake
brianm: when the wombat cannot see it has options:
mich__: Obviously, it cant do both
brianm: rule 1) turn on the light
brianm: rule 2) use a torch
brianm: rules 2 are incompatible
brianm: only one can be used
proyal: if the wombat was on fire, could it not see from the light of the flames?
brianm: proyal: hey, this is made up for example purposes =)
proyal: in your example, i would think that salience might work?
since once the fire is put out, the 'on fire' fact would be revoked..
brianm: yeah, actually it could, being on fire is obviously much more important
to resolve
0 writebacks [/src/java] permanent link
Thu, 08 Sep 2005A month of darcs later and I am hooked. Subversion is nice and all, but I'm using darcs for any self-hosted projects I do.
The only drawback is the install, build with GHC. Otherwise, it is gorgeous for distributed development.
2 writebacks [/tech] permanent link
Wed, 31 Aug 2005Just got email from Erin (hint, Erin, you need a blog (here is a pretty one to spur your imagination)):
Contract is signed. We're officially "Professional Ruby Developers". :)
Chariot has its first (primarily) Ruby (on Rails) gig!
0 writebacks [/src/ruby] permanent link
Sat, 27 Aug 2005I'm glad Leo has returned from his "escape geekery" sabbatical! In particular I'd like to point out a post on changing how we write jarvar =)
Leo gives us some code:
iterate(
over( pairs(coll) ) )
.skipIf( keyIsInstanceOf(UnprocessableObject.class) )
.returning( arrayOf(Pair.class) )
.exec(
new Object(){Object process(Pair pair){
print( "%s -> %s", pair.getKey(), pair.getValue() );
}} );
What caught my eye is that it looks like a bunch of stuff I've been doing lately when building API's:
handle.inTransaction(new TransactionCallback() {
public void inTransaction(Handle handle) throws Exception {
handle.prepareBatch("insert into something (id, name) values (:id, :name)")
.add(new Something(1, "one"))
.add(new Something(2, "two"))
.add(new Something(3, "three"))
.add(Args.with("id", new Long(4)).and("name", "four"))
.add(Args.with("id", new Long(5)).and("name", "five"))
.execute();
}
});
assertEquals(new Integer("5"),
handle.first("select count(*) num from something")
.get("num"));
or
AsyncHelper.tryUntilNotInterrupted(new AsyncHelper.Helper() {
public void cycle() throws InterruptedException {
pendingWriteFrames.put(new FrameBuilder(Stomp.Responses.ERROR)
.addHeader(Stomp.Headers.Error.MESSAGE, message)
.toFrame());
}});
}
which a popular couple libraries with reasonably well respected client api tends to do
return (Thing) getHibernateTemplate().execute(new HibernateCallback() {
public Object doInHibernate(Session session) throws HibernateException {
return session.createQuery("select s from Thing s where " +
"s.wombat = :wombat and " +
"s.mouse = :mouse")
.setString("wombat", wombat)
.setString("mouse", mouse)
.uniqueResult();
}
});
All of these examples use a common idiom from Ruby, Objective-C, and (I am told) Smalltalk -- message chaining. It leads to some really natural feeling and expressive code (which can look awfully funny at first, but you get used to it really fast, and then get frustrated when you cannot use it.
Next time you write a method with no return (a void method) consider
having it return this instead. It breaks JavaBeans,
sadly, which explicitely say a setter returns void, which limits its
usability as the JavaBean naming convention is one of Java's serious
strong points. It works nicely for chaining action style things though!
I blame Ruby. Leo blames Python. Gavin has blamed Smalltalk (he doesn't look old enough to be a Smalltalker, who'd have thunk). I don't know who gets blamed for the callbacks and templates in Spring, or to what they attribute the practice =)
2 writebacks [/src] permanent link
First, stomp won. It was close. =)
Second, am revoking the RC status to make a (backwards compatible) protocol change. Chatting with James and Joe (Joe is doing a .NET client, woot!) while fighting with WebLogic lead to an easy way to handle transactional consumes, so I'm going to finish up client ack and add support for transactional message acceptance before calling it 1.0. As Joy is out of town, that means probably by Sunday night =)
The haus kindly offered to host work, so if you're making a client, building an adaptor, or implementing a server in Erlang, drop me a note.
Oh yeah, James noted that a JDK 1.1 compatible client would be possible over on TSS when someone asked about it =) JMS on JDK 1.1, who'd have thunk.
0 writebacks [/src/stomp] permanent link
Thu, 25 Aug 2005Kevin Barnes has a great post looking at different language philosophies.
He captures the differences between camps well, and though I straddle some middle ground, I prefer the Freedom languages for actual programmering =)
0 writebacks [/src] permanent link
Tue, 23 Aug 2005
Rails Talk at ApacheCon US 2005
Looks like my Rails talk was accepted for ApacheCon US in December. Woot!
0 writebacks [/tech] permanent link
Hmm, got a fair chunk of feedback in the mere seven hours since I talked about the name change telling me not to do it! Mostly it boiled down to "TTMP sounds like a protocol, Stomp doesn't." Though most folks put it more eloquently.
I was shocked, I didn't realize people felt strongly already. Okay, chance for feedback =)
My thought is that Stomp is more memorable and less likely to be confused with smtp, http, etc in the ears of folks who think "r freaking clue?" when they hear RFC. As was pointed out to me, sounding like a protocol name is not a bad thing for a protocol, on the other hand. Other names considered included tomp (which does a nice stomp for the ssl wrapped version), stmp (which is far too close to smtp for my taste), and Johan (my generic name, like Bob).
The best benefit of stuff still in development is that it is malleable. Seriously, some feedback is appreciated and I'll hold the ax off on the name change for a bit -- names are important. I won't go through months of wiki voting (a la echo/atom) for a current developer community of four though =)
On the other hand, is it good when the unsolicited feedback "the name change is a bad idea" outweighs unsolicited technically feedback 3:1? Either we're doing something right with the protocol, or... ? Regardless, I love unsolicited feedback, period, as it means people care enough to step forward!
1 writebacks [/src/ttmp] permanent link
Finally found a good name for the little streaming text oriented messaging protocol I've been working on =)
Stomp! (Bang optional)
(TTMP has always been a temporary (TMP, get it?) working name until the right one came along. Names are important in computing.)
More goodness to come!
0 writebacks [/src/stomp] permanent link
Been talking about the wicked greatness that is Ruby a lot, time to give Java some lovin'. Java offers a few things that you can certainly do in Ruby, but for now are actually a lot easier in Java. Basically Ruby has the general cases for Java's special cases -- sometimes the optimization for the special cases works best. Let's jam to some SOA goodness!
The plan:
- ActiveMQ REST Connector with "Message Driven POJOs"
- Dojo Toolkit
- AspectJ
- OJB
Implement distributed Smalltalk style MVC:
- Push commands to a queue (using Dojo) as the controller -- queue is listened to by a Dr. Pojo which simply loads appropriate domain objects and operates on them.
- Use AspectJ to instrument them appropriate domain objects to post change notifications to appropriate topics using a standardized naming convention (Coarse notification variety, probably, will experiment)
- Subscribe to topics to register as change listeners on the model via Dojo and that REST api to ActiveMQ.
- Do the heavy lifting in Javascript in the browser -- woot!
Bennies include: Only state live in the app server is for the duration of whatever the command invoked, asynchronously, is operating on. All user-specific state can be stored in memory in the Javascript VM. 3rd party API for arbitrary alternate client is baked in. Problem domain for the application can be modeled solely in terms of the problem domain -- aspects handle any notifications needed. Etc.
1 writebacks [/src/java] permanent link
Mon, 22 Aug 2005Ian Holsman has written a ttmp client for perl. Woot!
0 writebacks [/src/ttmp] permanent link
Sun, 21 Aug 2005
TTMP Protocol Specification 1.0 Release Candidate 1
Well, I promised a cleaned up TTMP wire protocol before the end of the weekend, and here it is. I also updated the ruby client to be more useful. A tutorial and expanded docs are coming, but the main change is that you add listeners on specific subscriptions and for receipts instead of using a single listener for all messages.
The ActiveMQ implementation supports the 1.0 Release Candidate 1 protocol spec.
Meanwhile, Aaron is sitting next to me hooking a more recent build of ActiveMQ (which supports TTMP) into Geronimo =)
4 writebacks [/src/ttmp] permanent link
Fri, 19 Aug 2005James Bach posted a wonderful entry a month or so ago which I just found via Glenn Vanderburg talking about the incredibly true idea that all circumstances are at least somewhat different =)
No point parroting James, go read him.
1 writebacks [/src] permanent link
Thu, 18 Aug 2005
One more Enterprise Service for Ruby ;-)
So, let's see, nothing like an interactive session log to show things:
brianm@kite:~/src/ttmp$ irb
irb(main):001:0> require 'ttmp'
=> true
irb(main):002:0> t = TTMP::Connection.open "brian", "wombats", "localhost"
=> #<TTMP::Connection:0xb834 @started=true, @socket=#<TCPSocket:0xb564>>
irb(main):003:0> t.on_receive { |m| puts ">> #{m.body}" }
=> #<Proc:0x0005b2c0@./ttmp.rb:51>
irb(main):004:0> t.subscribe "a"
=> nil
irb(main):005:0> t.begin
=> nil
irb(main):006:0> t.send "a", "hello queue a"
=> nil
irb(main):007:0> t.send "a", <<-EOM
irb(main):008:0" Longer message to queue a..
irb(main):009:0"
irb(main):010:0" lalala =)
irb(main):011:0" EOM
=> nil
irb(main):012:0> t.commit
=> nil
irb(main):013:0> >> hello queue a
>> Longer message to queue a..
lalala =)
Hmm, that is nifty. So what though? Well, this will work transparently between ruby and Java (via the JMS API) -- right now just on the most performant and easiest to use open source JMS implementation around (just my opinion) -- but with just a couple hours work, any JMS implementation.
I was going to wait to post much more about this until I'd had a chance to push together Perl, Python, PHP, Bash, PLT Scheme, and maybe an SBCL implementation of the client -- but comments on the TSS kinda pushed me over the edge, so I'll just post now =)
The TTMP protocol has changed some since my last post, but the basics are the same. It will be changing some more, but a solid 1.0 protocol spec should be available after this coming weekend (unless I have too much fun up in NYC with Patrick). The implementation for ActiveMQ is in subversion now and should be available with the upcoming 3.1 release -- you are welcome to grab the snapshots, or build one to play. Once I am happy I'll put a tarball up with a default ttmp handler, alongside a default optimized binary (for the Java and C# clients).
Ruby isn't the threat to Java, vendors jockying for advantage at the expense of their users in the standards game is the threat to Java. I wholly agree with Jason that Java is being disrupted though.
Ruby is a fantastic language, but not one which will "supplant" Java (I still believe that whatever the next dominant language is, it will look and smell like Scala). I have a sneaking suspicion that language diversity is picking up. Sure, something will dominate like Java, C++, Fortran, Pascal, COBOL, etc have -- but for a while there won't be. Ruby is one option -- it has been my preferred language for a few years -- and I use it where I can and where it is appropriate. That is actually more and less places that might be thought. I cannot think of the last significant Java project I have worked on which didn't have at least some one-off ruby code generators, for instance. Will I stop writing Java? Heck no -- I like Java, for all its foibles and flaws (just as I do Ruby, for all its foibles and flaws). Pick the best technology for the job -- sometimes that is even Scheme (which I used most heavily when my primary role was systems admin stuff, go figure) =)
4 writebacks [/src/ruby] permanent link
Fri, 12 Aug 2005
You know you've been doing too much Java when...
You do this:

I'm glad it's Friday.
3 writebacks [/src/java] permanent link
Thu, 11 Aug 2005MrG gets interviewed. I cannot stress enough how good Guillaume has been for Groovy. He's really stepped up over the last year. Go Guru G! Now if we can just get him to grow a beard...
0 writebacks [/src/groovy] permanent link
Wed, 10 Aug 2005I beat on the ttmp wire format for ActiveMQ some more, connecting and sending messages work (see transcript!):
brianm@kite:~$ nc -v localhost 8899
localhost [127.0.0.1] 8899 (?) open
CONNECT
login: brian
passcode: wombat
^@
CONNECTED
session:ID:kite.local-63748-1123682509041-1:0
^C punt!
brianm@kite:~$ nc -v localhost 8899
localhost [127.0.0.1] 8899 (?) : Connection refused
brianm@kite:~$ nc -v localhost 8899
localhost [127.0.0.1] 8899 (?) open
CONNECT
login: brian
passcode: wombats
^@
CONNECTED
session:ID:kite.local-63760-1123682587710-1:0
SEND
destination: /queue/example
This is an example message, nothing fancy, an unfortunately... we won't see the result =(^@
^C punt!
brianm@kite:~$
Unfrotunately, while subscribing ~works (the consumer is pushed to activemq) I cannot seem to get ActiveMQ to actually feed messages into the protocol handler =( I am doing something wrong (as I can move messages using other protocols (and crossing from ttmp to ActiveMQ native is easy -- I am sending via ttmp and receiving via ActiveMQ's default tcp protocol -- tracing highly asynchronous, multi-threaded (and worse, select/ring-buffer style) code isn't easy.
Anyway, current working doc for the ttmp protocol will remain posted online.
1 writebacks [/src/ttmp] permanent link
Mon, 08 Aug 2005Beat on TTMP some this evening, after doing a bunch of work on a top-secret project this morning. The best part is that I have no idea which project is more fun =) Yea!
Anyway, current state of the TTMP connection handshake:
Client sends a CONNECT frame:
CONNECT
login: [login name]
passcode: [passcode]
^@
Please excuse the use of [foo] instead of <foo> for required things. I am too lazy to escape them =)
Okay, so client sends that, server will either reply with an error indicating a failed login:
ERROR
message: [error message]
^@
Or a CONNECTED
CONNECTED
session: [session id]
^@
Yeah! You are connected. The login handshake has been implemented
in ActiveMQ. It's a bit hacky because TTMP is much less chatty than the JMS spec, so the WireFormat implementation has to pretend there is more traffic than there really, but that is an implementation detail =)
I am not sure about requiring the session on every
frame now that it is definately a connection-oriented protocol. The
socket is certainly trackable, and requiring the session implies you
can change sessions, which isn't something I think I want. Will muck
around some, but am thinking hard of dropping that.
0 writebacks [/src/ttmp] permanent link
Sat, 06 Aug 2005
Trivial Text Messaging Protocol (working name)
Chatted with James and Max (no link for Max, don't really know him) about the trivial MQ wire protocol/format I'd talked about previously. We all rather agreed that it should be TCP based, despite the ease of implementation in a REST-y manner. We looked at BEEP, figuring we are reinventing stuff here (which we are) and BEEP is nice, and is optimizable, but it fails an important test, I cannot (easily) use the protocol by hand via netcat.
Current thought for messages is borrowing a lot from HTTP and SMTP -- they both work really well, after all =)
SEND ttmp://example.org/queue/EXAMPLE
session: 445a99490cdaed59122962bc1fd98051
reply-to: ttmp://example.org/session/445a99490cdaed59122962bc1fd98051
This is the message body^@
Should be pretty self explanatory. We dropped the xml encoding of the message, line-oriented is equally (or more) clear, less verbose, and less problematic for encoding XML as the message body.
Now, some stuff I haven't discussed, but have been thinking
about. This looks, smells, and even acts in many ways like SMTP. It
isn't. SMTP supports a lot of stuff I have no desire to
support. Also, TTMP (working name) requires a bunch of stuff you
could never retrofit onto SMTP now -- like requiring authentication,
period (the session is a key obtained from logging
in). I strongly suggest any implementation use SSL instead of raw
TCP in order to prevent replay attacks, but that is up to the
implementation).
"Automatic" reply-to has been dropped, a given connection will
always be given a receive-only queue it can listen on as part of the
login process, that is the recommended reply-to if you
need a private temporary queue. Implementations may delay actually
allocating any resources to said temporary queues until such a time
as a message is sent, so it is really just reserving a name.
The last interesting bit of the message format is the ^@ -- that is a null, ASCII-0. It is a specific known terminator and the one character disallowed in the message body. Yes, this will negatively impact performance compared to a message body size in the headers, but I cannot add up sizes when using netcat, so that option isn't there.
Probably need to figure out the commands next, and maybe provide some EBNF for them in order to start making it a properly formal spec. Feedback much appreciated!
5 writebacks [/src] permanent link
Fri, 05 Aug 2005Listening to Adam Bosworth's talk on scaling database stuff from the MySQL Users Conference. Adam is, as usual, very interesting to listen to, and quite inspiring.
It got me thinking about a side-project I have been pinging on for a while, setting up a solid cross-platform (which to me means Ruby -- Java -- Perl) messaging (as in MQ) system. I've been working with ActiveMQ because it is open, fast, and reliable + James has been very willing to help with cross-platform stuff. I think we have just been taking the wrong approach to cross platform.
Right now ActiveMQ has its openwire protocol. This protocol is derived from a bunch of constants defined in the Java sources, and ActiveMQ uses it to build a bunch of different marshalling/unmarshalling code in a variety of languages. In effect, the protocol is dereived from the capabilities of the source. This works if the goal is to provide the full capability of ActiveMQ on any platform, but... that is not what I want. I want basic, reliable, messaging between arbitrary platforms based on an easy wire protocol.
There is a SOAP spec for this. Okay, yeah, let's not go there.
So, what do we actually need? Well, a simple and effective protocol with a reasonable lowest common denominator -- text. We need to be able to subscribe, by event or by poll. Let's start with what a message looks like:
<message>
<headers>
<destination>http://messaging.example.org/queue/SAMPLE</destination>
<reply-to>auto</reply-to>
<x-header id="something">something else></x-header>
</headers>
<body>
Message Body Goes Here
</body>
</message>
That's it. Let's look at some details.
For the body element, we'll say that it must be text,
must. It may not be xml. I think sending xml may be great, but CDATA
it if you do. Encoding for XML in the body is CDATA, period. Clients
can run it through a parser themselves.
For the headers, I'll start right with the standard JMS headers. JMS works really well, good starting point.
- destination
- Absolutely relevant here, and we'll force the message to contain the destination so that we can do routing at this level. Desinations will be urls in WOMP's scheme of things.
- delivery-mode
- May be PERSISTENT or NONPERSISTENT, defaults to... default is configured on the provider =)
- message-id
- We'll follow the JMS spec on this one. It will be assigned by the provider, possibly being returned from the mechanism used to send the message. It will be an error for a client to specify this.
- timestamp
- Plunked on by the provider when the message is accepted by the provider. Values assigned by client are ignored.
- correlation-id
- Optionally provided my the client.
- reply-to
- Destination url the client expects to receive a reply on. The special value 'auto' indicates that the client wants to receive a temporary one in the response to the send operation. In the case of auto, a queue will automatically be created and the client "subscribed" -- whatever that means for the transport in question. No default as we'll make "fire and forget" the logical default operation.
- redelivered
- Follows JMS rules, meaning provider deals with it. Basically to help consumers de-dupe messages.
- type
- Always text in JMS terms, header doesn't exist for us.
- expiration
- We'll use a time-to-live header instead as an offset from the timestamp. Default will be "forever."
- priority
- Stick with the JMS 0-9 values, what the provider does with it is up to the provider. Defaults will probably be normal, definately not required.
- x-header
- Arbitrary header which must be passed along with the message.
So far, nothing fancy. It's worth dealing with JMS semantics as this is just a wire format (and I'll go ahead and spec a couple transports as well), ideally one which can have implementations against any messaging system. Universal type 4 jms driver ;-)
Okay, so we have a "send message" format. What about receiving? Let's define a message to say we are interested in receiving messages. As JMS has done a nice job of the heavy lifting, we'll go ahead and stick with semantics from that and just define a wire format for messages to subscribe:
<subscribe>
<destination>http://example.com/queue/SAMPLE</destination>
</subscribe>
So, that says we are interested, the subscribe operation may return
a result, depending on the transport. So far I am worried about this
transport-dependent stuff. We'll have to work that out. The
durable element is optional and says the subscription
is durable in jms terms. There is an unsubscribe
message as well to remove interest in a destination.
So, looking at the format, it is verbose and limited. I love it.
A REST style transport should be dirt simple, and may be the first go.
I think *too* complicated already. I want to drop a bunch of the JMS stuff to simplify further, but need to think about the right way to do that.
A TCP based transport is also dirt easy to envision. It is actually easier. May do this first, dunno. Need to think about it. For that I'd do an awfully thin wrapper around ActiveMQ's JMS API as a first implementation =)
Both will be slower than an optimized binary protocol, but WOMP (Wide Open Messaging protocol) is about interop, not about performance. ASN1 is more efficient than XML, after all...
5 writebacks [/src] permanent link
Thu, 04 Aug 2005Okay, publishers, listen up. I want short books which don't reteach me what I already know. Technology specific books (Manning, Wrox, APress, etc) in particular spend 480 pages explaining what model2 is, for example, when it is a book on Struts 4.7 -- don't. How about a series of short books which presume knowledge of obvious antecedents?
- diff -u Struts JSF
- diff -u Entity-Beans OJB
- diff -u Spring EJB3
- diff -u Java Ruby
- diff -u Tapestry JSF
Seriously =)
2 writebacks [/tech] permanent link
Wed, 03 Aug 2005The "right way" being promulgated "right now" for a lot of application design is kinda, sorta, maybe over abstract I think.
Let's look at a perenial favorite, talking to a database. We'll go ahead and consider JDBC to be the lowest level API available for chatting with the DB. Place on top of that OJB|Hibernate|IBatis|Cayenne|JDO|TopLink. Now, you had best not depend on the particular o/r library, so you build a DAO abstraction which allows you to change them. Now, DAO's are the gateway between the the "resource tier" and the "middle tier" so you write a service which uses the DAO and mucks with whatever it returns. Maybe you use the service from another service, whatever. Of course eventually you want to let someone see this data, so you write a service facade to expose to the "view tier." If you are old school you map to a DTO layer for crossing the middle/view barrier, if you are new school you hope your query back whenever ago fetched everything whatever on the other side needs, because you are not allowed to know, after all.
0 writebacks [/src/java] permanent link
Tue, 02 Aug 2005Been using darcs for personal projects for a while. Other than the epic of getting GHC to build on my Mac, it is really nice. I think I'll keep using it for personal stuff, is really too nice. For shared stuff will prolly stick with subversion, less trouble for other folks.
2 writebacks [/tech] permanent link
"useful" apps are in PHP because folks using it are more interested in functionality than technology
0 writebacks [/src] permanent link
Fri, 29 Jul 2005
Web State Management Using Externalized Dynamic Scoping
Once upon a time I asked for better scoping in web applications. Here is a possible way to do it. The idea is to use a system based on dynamic scoping -- the type of scoping you get in elisp, for example. What we see most, now, is lexical scoping. Java, C, Ruby, Common Lisp, Python, etc all use lexical scoping. Lexical scoping says that things are in scope based on where they are defined lexically. It is so fundamental that the idea of alternatives seems kinda weird. Well, there are -- but they have proven less useful in general. One of those is dynamic scoping. That is scoping such that variables down the call stack are in scope rather than what is in the source code. Emacs Lisp (elisp) works this way.
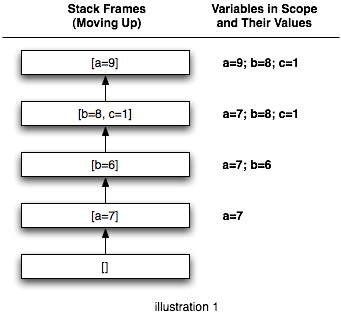 Illustration 1 shows an example of a scope stack. The box at the bottom represents the root, or base, of the stack. Additional frames are pushed onto it. A given variable is stored in a specific frame. The first variable we store is
Illustration 1 shows an example of a scope stack. The box at the bottom represents the root, or base, of the stack. Additional frames are pushed onto it. A given variable is stored in a specific frame. The first variable we store is a set to 7. It is stored in stack frame #1. We push another frame, and store b in that frame. Now anything using frame #2 for variable resolution will see both a and b. In stack frame #3 we reassign b. The new value is said to mask the old value. Dereferencing b in stack frames #3 or #4 will give you 8, but the previous frames still retain the old values.
You can think of a series of web requests as traversing up this stack. Each request pushes another frame on the stack, and any new state for that request is stored in that frame. The accumulated state of the flow of requests is available to the current request. Use of the back button pops a frame off the stack, moving you back to the previous state -- and the values stored at the time you were originally at that point.
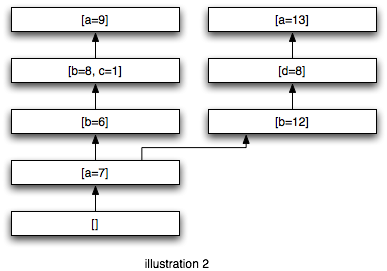 Even nicer, it allows you to fork the stack by opening multiple tabs (or windows for you IE users ;-) and continuing along. Illustration 2 shows a forked stack. Because all application state is dereferenced from the point of view of the current frame, you will maintain a correct view for a given path. You have two logical shopping carts as soon as you add something to it in a different window. Cool!
Even nicer, it allows you to fork the stack by opening multiple tabs (or windows for you IE users ;-) and continuing along. Illustration 2 shows a forked stack. Because all application state is dereferenced from the point of view of the current frame, you will maintain a correct view for a given path. You have two logical shopping carts as soon as you add something to it in a different window. Cool!
Nice in theory, but does it work? I put together YAWF to see how it works in practice. At its heart, YAWF is just a registry which can record and repopulate component state. Given this component:
package org.skife.sample;
import org.skife.yawf.State;
public class Hello extends Greeting
{
private String name;
public Hello()
{
this.setName("[Name]");
this.setSalutation("[Salutation]");
}
@State
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
YAWF state works on JavaBean properties. Any property can ask to have its state managed by annotating the getter as above. It requires that you have a getter and setter, though they don't have to be proper JavaBeans syntax if you are willing to provide a BeanInfo per normal JavaBeans stuff. Anyway, on to the fun stuff, let's manage some state. We'll start simple:
public void testBasicRecording() throws Exception
{
Frame frame = new Frame();
Hello hello = new Hello();
hello.setName("Brian");
frame.store(hello);
Hello another = new Hello();
frame.populate(another);
assertEquals("Brian", another.getName());
}
public void testStoredInParentFrame() throws Exception
{
Frame frame = new Frame();
Hello hello = new Hello();
hello.setName("Brian");
frame.store(hello);
Frame child = frame.createChild();
Hello hi = new Hello();
child.populate(hi);
assertEquals("Brian", hi.getName());
}
Nothing fancy here, you can see the rest of the tests and whatnot to make sure it abides by the rules I described in the TestFrames class. Nifty.
Now, because frames basically store name-value pairs, we have to assign a name to things. The default name for a field is the fully qualified name of the class declaring the getter, follows by a hash mark, followed by the property name. If you don't like that naming convention you can assign any arbitrary name to a piece of state, such as in the Greeting class.
Now, as it stands this is just a general state registry kind of thing, let's make it work for a web app. To do that we introduce a mechanism to serialize out a frame, the FrameEncoder. This one does a bare-bones level of encoding -- it serializes the frame, gzips it, encrypts it, base 64 encodes, then url encodes. This gets the size to something reasonable, and lets us stick the whole stack on the url. It could be optimized further by flattening the stack before serialization, doing custom serialization of the value storage system, etc, but the gzipped serialization was enough for this =)
Once we can serialize our (state) stack out, we need a convenient way to play with it from the web. A simple servlet filter and a couple associated utility classes do the job so that we can have a small sample app in a jsp. The important stuff in this JSP (yes, with scriptlet, is is just a sample) starts with the stack management:
<jsp:useBean id="hello" class="org.skife.sample.Hello" scope="request"/>
<%
Frame frame = Framing.getFrame(request);
frame.populate(hello);
if (request.getParameter("name") != null)
hello.setName(request.getParameter("name"));
if (request.getParameter("salutation") != null)
hello.setSalutation(request.getParameter("salutation"));
frame.store(hello);
%>
Which just records some form parameters. Setting them is likewise pretty simple:
A Form:
<form action="<%= response.encodeURL("index.jsp") %>" method="post">
<label for="name">Name </label>
<input id="name" type="text" name="name" size="40"/>
<input type="submit" value="Change Name"/>
</form>
The key thing is to make sure to always URL encode the links so that the stack can be copied into the url =) Now you carry around, on each link, a copy of the stack (~350 characters usually, after gzipping). The application state is encrypted (algorithm and key configured in the web.xml) to prevent meddling, and you have no http session to worry about replicating. You have a seperate stack of state information for each flow. You a correctly behaving back button. Pretty nice.
YAWF is really a proof of concept, but is a pretty decent one. There are a ton of optimizations that can still be made, but it has proven to me, anyway, that the concept has some legs. If you want to play with it, I have the sample app (the single jsp anyway) set up so that you just need to untar, and ant sample to start it up. It does require jdk 1.5 (note the annotation usage). Have fun!
1 writebacks [/src] permanent link
Thu, 28 Jul 2005
A Quote for Robert (at Agile 2005)
Robert left a note for me, I figure I can return the favor =) A great quote regarding software development:
The most deadly thing in software is the concept, which almost universally seems to be followed, that you are going to specify what you are going to do, and then do it. And that is where most of our troubles come from. The projects that are called successful, have met their specifications. But those specifications were based upon the designers' ignorance before they started the job.
A beer (or other beverage of choice) next time I see you to whomever can first properly attribute the quote, and when it was made =)
2 writebacks [/src] permanent link
Tue, 26 Jul 2005
Agile Open Source (How's that for buzzword compliant?)
My friend, Robert, has been talking a lot about agile methodologies and open source. He, with David Kane, did a workshop at Agile 2005 on How to apply agile development methods in open source projects. Anyway, he posted some feedback from it, which I wanted to comment on -- as a case study he used is Mesquite, which I have been on the periphery of for a while.
Robert posits that the technical aspects of agile development can apply perfecty to open source development. I kind of rate this a "duh" -- this is things like continuous integration, ubiquits version control, test first, etc. I don't think anyone is going to disagree here. It is seeing if there is much that can be done with the agile management techniques that is intrigueing. Iteration planning, blog as substitute for scrum meeting, etc.
One of the fundamental pieces of most agile methods is that time is fixed and scope is not. Most open source projects don't fix time -- unless there is funding it is very tough to maintain any kind of consistent velocity, which makes fixing time pretty pointless. An approach Robert has talked about is fixing time-units or even (gasp!) fixing estimated scope -- and being actively willing to re-estimate effort levels for a story and adjust the iteration target to stay on a target number of points. I am phrasing this differently than Robert has, but it is how I describe what I have watched him do =)
Anyway, I am looking forward to seeing Mesquite written up as a case study -- it will make a fantastic one I expect.
0 writebacks [/src] permanent link
Mon, 25 Jul 2005
ApacheCon EU 2005 Project Notes
Axis2 looks very interesting. It is a serious re-working of Axis to function in a message/document passing system rather than binding to RPC. It looks to have much better support for XML binding and WSDL-first. The only XML binding systems in place (I believe) are raw Axiom and XMLBeans. Dims recently left a note for me saying he'd written added xpath support to Axiom via Jaxen (ah jaxen, sweet sweet jaxen). From an outside POV, Axis2 and XFire look more or less the same.
MySQL clustering looks pretty impressive. I really wanted to get a chance to talk with Jan, but it never happened =( I have a pretty low baseline appreciation for MySQL, but with InnoDB they have become much more worthy of consideration. GPL'ing the drivers is pretty questionable, but they own em, so hey. I need to find some high-memory machines and play with their cluster support some.
APR is amazing. Amongst everything else, it has a really nice memory management compromise with the pools.
Lucene4C is a bear to compile, unfortunately. The idiommatic C interface is a good thing (incomplete so far, though), but getting the beast to build is... not so fun.
Derby is rocking. This little DB ain't gonna be little for long. I pestered the Derby folks about all my sore points -- and they'd all been resolved! Heck, you don't even need the system property anymore, I am told, but can specify a full path in the jdbc url instead! Not sure how this will work with derby properties, but need to experiment. Embedding multiple instances in one VM is possible via classloader hackery -- but they are working to make this easy to do, or at least provide good examples.
OSGI is much more interesting than I previously thought. Sylvain gave me a good explanation of it, and I am impressed. Sylvain is a madman -- like all the Cocooners I guess, but possibly more so than others.
Finally, looks like the Subversion Classloader is going to happen. Awesome!
1 writebacks [/tech] permanent link
Sun, 24 Jul 2005And dirt tired. Will do writeups on a few specific sessions when I wake up.
1 writebacks [/tech] permanent link
Fri, 22 Jul 2005
Rails, Rules (Drools!), and Managing OSS Slides Online!
Slides from the three talks (on Ruby on Rails, an Intro to Rules Engines (using Drools), and managing business risks associated with open source) which I gave at ApacheCon EU are available online from Chariot Solutions now. The page has quite a few -- mine are the top three (most recent) as of my posting this (7/21/2005 and 7/22/2005 respectively).
Hope you find them useful!
0 writebacks [/tech] permanent link
Wed, 20 Jul 2005So, I wanted to post some trackbacks to blogs.apachecon.com and, well, I don't use a fancy blog entry editor thing which can do trackbacks for me. In case anyone else is in the same situation, here is a little command line tool for posting trackbacks: trackback. Unlike the actual spec, all fields are required for this client, sorry, is 10 minutes of coding between sessions =)
brianm@kite:~$ trackback -h
Usage: trackback [options] excerpt
Options:
-b, --trackback-url VALUE The url to post the trackback to
-u, --url VALUE URL of the response post
-n, --blog_name VALUE The blog name for the trackback
-t, --title VALUE Show or hide result url in output
-h, --help Show this message
brianm@kite:~$
If you don't specify a part on the command line it will prompt you for it -- should be friendly enough.
1 writebacks [/src/ruby] permanent link
I spent far too much time at the hackathon fighting with gcj. It has been for a good cause though =) Thomas Dudziak and I, after mucking for a while, are leaning towards working with the lucene4c rather than the straight gcj. Lucene4C uses the gcj'd one as well, but puts a more idiommatic C api in front.
In addition to that stuff I played taskmaster with James to flesh out the ActiveMQ bindings for Ruby I started a while back. It looks like we'll stick with the code generation approach for message marshalling/unmarshalling -- it is handy as *all* of the openwire protocol handlers are code generated from the protocol spec. Pretty cool. James's estimate of the openwire protocol performance is about 10% behind the most highly optimized native -- but it has some deeply interesting encodings for performance. I'll take the 10% performance hit for ease of implementation. Once it's up and running I can worry about speed (and maybe do a C library if we really care). We *hope* to have something roughly usable possibly as early as monday. Don't hold me to that, it presumes that I find a nice way to do UTF conversions.
The Cocooners are sick and twisted people (in a good way). Over various beers we got to talking about obscure but... just possibly useful hacks. Tunneling over pings and tcp sequence id's, for instance. On a potentially more interesting note we got to talking about the Groovy classloader which groks maven repositories and between Torsten and Upayavira they had the most brilliant idea I have yet seen. Forget using the maven repository, use koders.com, google, and viewcvs with a compiling classloader. Given import org.apache.Wombat statement it can go get CVS head, compile it, and load it... ;-)
In a Geronimo talk right now. Every other sentence it seems is "Aaron Mulder just added ..." =) Aaron got credit for one of Erin's things (pretty startup) -- though I am not sure who actually coded it. Go Aaron!
0 writebacks [/tech] permanent link
Sat, 16 Jul 2005Okay, so day one is fudging it, the conference hasn't started, but I am here, so is my day one =) Had dinner with Rich Bowen in the hotel cafe. Who'd have thunk currywurst would be really good? It is. Several other folks are supposed to be here, and Rich spotted Sander, but I've not run into anyone. Looking forward to meeting up with Thomas Dudziak (a fellow (and much more productive than me!) OJB'er) tomorrow.
Flight was uneventful (yea!) and the train ride down from Frankfurt turned into a nap. Now I am trying to stay awake until a reasonable hour to try to get my internal clock on local time. I'm looking forward to the hackathon starting up. Okay, tired and rambling, off to wander around Stuttgart some more.
0 writebacks [/tech] permanent link
Thu, 14 Jul 2005I have to jump on this, come on! The wonderful "scalability" stuff jumps up again.
Scalability == ability to throw hardware at problem in order to handle more load. A reasonable measure of scalability is plotting the load volume (number of concurrent users, transactions per second, messages per second, whatever) against the hardware volume (I use volume as you can scale "vertically" instead of "horizontally" -- both have their place). The closer the function is to linear the better (unless you can find one which allows better-than-linear scalability, in which case please email me!).
Language, library, and platform are almost wholly irrelevent when it comes to scalability. This is almost pure system and application design stuff. Almost any significant application will have state -- heck even google does now (when you log in and get that customizable news page). State and I/OP are the usual killers of scalability. The problem is that the easiest way to fix one hurts the other. So, you play games =) I/O is, in the end, a harder problem, so most folks solve it first -- get big fat switches and lots of machines to spread the traffic around. This makes state way harder. Harder, but far from impossible.
A really nice "real world" write-up on state management growing pains comes out of a (so far) annual talk on LiveJournal (supposedly it gets 5 times the traffic as slashdot, and just referral traffic from slashdot is enough to kill at least 80% of web apps based on anecdotal evidence).
The solutions they talk about aren't the only way to go, but it is one with lots of detail publicly available, so it is a nice one to use as a reference. State management was killing em, basically. So, how do you manage state? The classic LAMP answer is "share nothing" -- which DHH talks about in a way I personally disagree with. To him "share nothing" means share nothing in memory between app server instance but go ahead and have shared state pushed out to some external repository. By that definition all the app servers he talks about which don't work that way (ie, the Java ones) in fact do -- use a RDBMS backed session store ;-) DHH's share nothing definition is a useful one though, as it is easy to do in any language or platform or framework or whatever. You still have shared state pushed to some other external resource. This is good.
Danga's answer is to push that shared state to memcached and accept the network hit to fetch it per-request. I rather agree with that option. Tangosol likes to adervtise a more sophisticated local/distributed cache setup and sticky sessions. That usually give better performance in exchange for slightly more complex deployment (you need sticky sessions). JGroups based distributed caches usually go for full replication, which is horrid for other reasons entirel =)
Notice not a word of what has been talked about here is language, platform, framework or whatever specific? That is because scalability issues are not framework or language specific. Does SISCWeb scale? That depends on how you design the system. It has nothing to do with SISCWeb.
3 writebacks [/src] permanent link
Fri, 08 Jul 2005So, yet another idea for a model for database access in applications. In ~traditional O/R mapping we tend to think of there being two things which are mapped to each other: the object model and the database schema. The "database schema" in this case is specifically the physical model. There is actually a third thing being mapped -- the logical model. In effect, with current o/r mappers we seem to come awfully close to matching the logical model in the object model. This makes sense -- the logical model is how we think about it a good object model is how we think about it. No wonder the two tend to be similar to each other.
In an ideal world you could have one model from which all else is generated -- orthogonal persistence from the perspective of the objects, tuples acting as substitutes for an interface in the object space from the perspective of the relational model.
How about we rewind database "technology" about thirty years and start talking about deriving the physical model from the logical model again -- and build the language-level (or library-level) constructs to correctly describe the logical model in the source -- then let the application derive a correct physical model from the logical model.
You can kind of do this now with an objects-first approach to modeling, but because object models do not enforce relational model constructs on themselves, you can blow it pretty easily. So, lets presume we are stuck with existing language constructs -- we cannot add the precise and accurate concepts of candidate keys and refvars to Java (or can we?), and types are definately Java types (or Ruby types, or C types, or Haskell types, whatever).
If you have rigorous developers you could map these in metadata -- objects-first/derived schema approaches used now do this to some degree. The current thought directions in the JDO2 expert group, and I am told in the persistence subset of the EJB3 expert group, leans towards keeping "mapping" metadata (columns, tables, keys, refvars, etc) at least conceptually seperate from "persistence" metadata (fetch groups, cascades, blah blah). How about we consider dropping the mapping stuff completely.
Every pragmatist reading this is shaking her head and saying "Brian's lost it and gone over to the dark side" -- but wait! Yes, there are legacy schema which need to be worked with. Heck, most new applications against new schema have legacy schema because we define the physical model before anything else (data first). But... this ain't the right way to do it, and maybe for new development we should consider doing things the right way. Ask the database vendors to support logical schema definitions and... integrate against the logical schema. Okay, yeah, I guess I am smoking crack. It's a nice idea, at least.
Something in this smells right, though, somewhere. I'm just not sure where.
1 writebacks [/src] permanent link
Wed, 06 Jul 2005
Apple, pay attention: Broken RSS (for Sam)
Apple folks: Go read Sam's blog.
Thanks!
0 writebacks [/tech] permanent link
I've been diving into the deep end of integration type stuff lately. I've done work in that arena before, but recently committed to learning craploads more about this stuff so, being myself (cheap, novelty junkie, open source whore) I've been poking sharp sticks into the open source stuff around (as well as the really expensive stuff -- some of which is pretty impressive).
Current playthings include:
- XFire: SOAP stack which plays nicely with others
- JORAM: JMS provider with a good reputation
- ActiveMQ: JMS provider with a good reputation (okay, I've used this before and quite liked it)
- PXE: recently open sourced orchestration engine with a good rep
- MULE: Possibly dated, but some people I respect keep plugging it, EAI broker
- Axis2: Cleaned up Axis, nuff said!
- ServiceMix: only JBI container I'm aware of which is usable right now
- WScript: Doesn't exist yet ;-)
Additionally, I fully agree with Steve Loughran's assertions in his Alpine paper. You are working with XML -- accept that. One of the things I really like about XFire is that I can use XMLBeans -- the most "true" Java-XML mapper I know of -- XOM would be nice as well. Something xpath-able at a minimum.
10 writebacks [/src/java] permanent link
Tue, 05 Jul 2005
Squeak! In Print! Pigs flying past my window!
I was nosing around a Barnes & Noble, one with a really awful technology section, the other day. Low and behold, they had a book which cannot even exist. I mean, who the heck publishes a book on Smalltalk?
Next we'll probably see something completely absurd, like a book calling Common Lisp "practical."
=D
0 writebacks [/src] permanent link
Mon, 04 Jul 2005Okay, I admit it, I like writing the mass of utilities, reinvented wheels, and heady edifices to the god of improving my own productivity. I'll sharpen the saw until it can cut sound. I am a library and framework writing junky!
Along comes RoR, now I find myself having to bear down and implement the actually business functionality for the application. Now it is "implement a SOAP/HTTP service to allow the Swing client to post back its offline changes" and "build an arbitrarily queryable entity-change audit report." This is no fun compared to writing a config file parser or persistence abstraction layer that can transparently swap out any number of relational databases, orm frameworks, ldap backends, or transaction log based in-memory systems!
These folks have their priorities all wrong. Programmers are supposed to write libraries for other programmers to use in order to write frameworks for other programmers to use in order to implement Excel and Visio like interfaces so that the business analysts can write useful(?) software.
2 writebacks [/src/ruby] permanent link
Fri, 01 Jul 2005
Where are the Components? The Haus!
I read another "Where are the components?" lament recently -- someone wondering where all this great, reusable, object-oriented code could be found. Dude, it's all over! All these frameworks people complain about having to choose between, all the libraries people complain about serving no reasonable purpose (except when suddenly you need them!). Crap, they're all over.
I bumped into a side growth of that -- the component instead of library or framework is out there too. As, over the last couple years, less intrusive component containers have been catching on, component integration has been moving to the component level instead of container level. If you look at Spring, it bootstrapped itself into relevance by bundling integration code for a bunch of different libraries, effectively componentizing those libraries. Now you see most new libraries componentizing themselves and making that their default mode of operation. Cool stuff!
Nosing around the haus again really drove that home. Almost every library-oriented project there (which is almost every project there) has hooks to bind to almost every container in even limited use. Crazy! Is a big library-integration lovefest.
0 writebacks [/src/java] permanent link
Thu, 30 Jun 2005In the Mortal Kombat DEEP VOICE: Impressive.
0 writebacks [/stuff] permanent link
Wed, 29 Jun 2005
jDBI 1.3.1 Released and added a Committer =)
Just released jDBI 1.3.1. It fixes a bug which only manifested in JDK 1.5. Annoying things, those platform version dependent bugs =( Thank you Patrick for finding it and figuring out the fix!
Along the way, I managed to force a commit bit onto him, even better!
This should be a drop-in replacement for anyone running 1.3.0.
0 writebacks [/src/java/jdbi] permanent link
Tue, 28 Jun 2005James pointed me to his code generators for binary marshalling/unmarshalling of ActiveMQ's wire protocol a while back. I finally got a chance to start beating on them. Behold the awful transition state from C# to Ruby!
#
# Marshalling code for Open Wire Format for ActiveMQTextMessage
#
#
# NOTE!: This file is autogenerated - do not modify!
# if you need to make a change, please see the Groovy scripts in the
# activemq-openwire module
#
class ActiveMQTextMessage < AbstractPacketMarshaller
def packet_type()
return 35;
end
#public override Packet CreatePacket() {
def create_packet()
return ActiveMQTextMessage.new;
end
#public override void BuildPacket(Packet packet, DataInput dataIn)
def build_packet(packet, data_in)
super.build_packet(packet, data_in)
end
#public override void WritePacket(Packet packet, DataOutput dataOut) throws
def write_packet(packet, data_out)
super.writePacket(packet, data_out);
end
end
end
Hopefully it will finish up smoother than it has started, but I am starting to get the hang of it ;-)
0 writebacks [/src/ruby] permanent link
Mon, 27 Jun 2005Just updated my google command line script to remove the dependency on the GPL'd Ruby/Google, as well as any other external libraries. All it needs now is a recent version (I am using 1.8.2) of ruby =)
brianm@kite:~$ google -h
Usage: google [options] query string which will be concatenated
Options:
-i, --start NUMBER Start index for results
-m, --max NUMBER Max number of results to show
-f, --[no-]filter Activates or deactivates automatic results filtering
-r, --restrict VALUE Restricts the search
-a, --[no-]safe Enable or disable (default disabled) filtering of adult content
-1, --lucky I'm feeling lucky
-H, --header Print field header on ouput (default disabled)
-s, --snippet Display result snippet in output
-t, --title Display result title in output
-u, --[no-]url Show or hide result url in output
-h, --help Show this message
Requires Ruby 1.8.1 and Ruby/Google ( http://www.caliban.org/ruby/ruby-google.shtml )
You can obtain a (free!) google key from http://www.google.com/apis/
exit
brianm@kite:~$
Have fun!
6 writebacks [/src/ruby] permanent link
Tue, 21 Jun 2005
Continuous Performance Testing Seminar in Philly
My employer, Chariot Solutions, is holding a Continuous Performance Testing seminar on July 19th in Philadelphia (from the flyer):
Two weeks before a system goes live, you get the bad news. It's not even close to meeting performance goals. You call an emergency meeting and find out that there are major design flaws that were only revealed under load. Basic tuning won't help, so you're faced with two unhappy alternatives: miss the release date or go live and hope to fix performance in a point release.
You're not alone. Early detection of poor performance is a difficult problem. Recent integration trends, from SOA to ESB to portals, have made performance analysis even more complex, and more critical. Yet, how can you accurately predict the performance of a system before it has been implemented end to end? Faced with this challenge and the high cost of leading test tools, most teams plan to test performance in the final stages of the project past the point at which core designs can be changed.
There is another way. In this seminar, we'll share successful strategies for continuous performance testing throughout the software lifecycle, using proven techniques and free tools. Upfront planning defines goals and metrics for each component. Early prototypes validate new designs. Application scaffolding and test automation provide nightly feedback with minimal overhead. Monitoring frameworks follow the application into production, allowing timely analysis in those critical first weeks after a release. Throughout the process, the architect is in control, focusing on the problems that really do need to be fixed now, while avoiding premature optimization for those that don't.
It's free, so register if you're interested.
0 writebacks [/tech] permanent link
Previously I had installed XMLStarlet (the fantastic xml command line tool) via fink, so it came prepatched. As I recently moved to DarwinPorts after running into too many things refusing to build from fink, I discovered XMLStarlet isn't there =( Anyway, it references foo.a style libraries instead of foo.dylib, so here is a trivial patch to allow it to build on OS X =)
0 writebacks [/tech] permanent link
Mon, 20 Jun 2005I have felt, for a long time, that the orchestration/BPEL/quasi-workflow space has been missing a big audience. Right now it is handled almost wholly by flowchart programming at one end, and bpel-in-emacs at the other end (which makes Jelly look nice). The flowchart programming model is painful for anyone that actually knows much programming, and scripting in XML is painful for anyone sane.
Now, the model for this orchestration component is that tech-savvy business analyst types, and non-programmer IT folks, can create reasonable orchestrations. This is fine and dandy. The fact is, however, that in a large number of cases it is actually being done by fairly sophisticated developers. I want to optimize that case. Imagine this:
import http://foo.org/employees.wsdl as employees
import http://foo.org/restaurants.wsdl as food
export start as http://foo.org/find_lunch-spot/
def start(employee_id)
employee = search.find_employee employee_id
if employee.xpath("/employee@title") == "Peon"
return food.find_cheapest
else
return food.search_menus_for employee.xpath("/employee/favorites/food")
end
end
Which compiles down to BPEL =) May need to add some additional declarations, maybe not. But doesn't this beat a flowchart?
2 writebacks [/src/java] permanent link
Mon, 13 Jun 2005So my wife is flying back from a conference today on Airtran. Her initial flight is significantly delayed such that she misses her connection. Airtran has no more flights from the connecting airport to her destination tonight. Not only won't they pay for her hotel room, they won't book her on a flight until 2:45pm tomorrow.
Flyer beware, Airtran will apparently screw you if they can.
1 writebacks [/stuff] permanent link
Sun, 12 Jun 2005
Dynamicity and Throwing Money at Problems
Howard's talk about reducing the amount of XML in Tapestry, coupled with Jamie Orchard-Hayes comment on tapestry-dev recently about how he likes the XML because it can be dynamically reloaded reminded me of a comment a coworker once made when describing some technology, along the lines of "that is the solution you get from throwing money at the problem, it solves the problem, but there is nothing elegant about it." That describes my feelings towards most of the XML configuration (and expression languages) in Java, right now.
In a post to the LL1 mailing list, someone (I wish I could remember who) posited the best definition of dynamic languages I have yet seen. The gist of it was that in a dynamic language, everything that can be deferred to runtime is deferred to runtime. Java doesn't support much dynamicity under this definition. All of the "#{foo} should be externalized" is often really trying to say "#{foo} should be deferred to runtime." XML has become the preferred way of doing this when any significant amount of deferring is going on. I posit that this is because there are cheap (bundled) and good xml parsers in Java, so you don't have to write your own (see lex and yacc). This is reasonable, and fair, and a solid chunk of what XML is designed to do.
However (you knew it was coming!) a lot of what is externalized in Java probably shouldn't be. It is going against the grain of the language. Java is designed to be type-safe, syntax-safe, memory-safe, stack(bashing)-safe, etc. We are all trying to circumvent that. It is like advertising a benefit of XML over HTTP being that "it lets you do RPC across those pesky firewalls those IT folks love." You throw away security (ie, knowing it will run) for... what? Yes, something valuable, but hold on, I bet it isn't even close to as valuable as you think because of some other stuff.
You claim to throw it away for configurability (sometimes valid, ie changing port tomcat runs on, sometimes wholly invalid, like changing the nature of a relationship in o/r mapping). You throw it claim to throw it away to reduce code (much more succint to do declarative execution off of some configuration, which is also valid sometimes, and wholly not other times). Finally, it is done for dynamicity -- being able to make changes at runtime and reload them (except you very rarely ever can (servlets in most cases you can, o/r mapping in most cases you cannot, for example)).
Now, seriously, consider throwing it away. If it is a configuration option only developers will make, put it in code. Try it out. If it is a systems-admin style config option, leave it external. Seriously, put developer configuration (your o/r mapping counts here, seriously, no admin is going to much with your o/r mapping, trust me), your port number ain't. You reduce code to save time, but most of the annoying hard to debug crap come sout of... yep, the xml configuration crap, so by reducing code you made it take an order of magnitude longer to make work. Nice one. Finally, for dynamicity -- give it up. Compiling Java is fast, and unless you really A) support runtime reloading, and B) actually even make use of it, then you are shooting yourself in the foot. Consider Beanshell, Groovy, Jython, or Rhino if you really need the dynamicity -- they are designed for it, Java isn't.
Now, short end note on expression languages. That is non-xml dynamicity for you (except for the wholly bizarre and disturbingly useful jxpath, which is, er wholly bizarre and disturbingly useful) in Java. It also is almost totally borked up. Seriously, don't create yet another expression language, just use GPath expressions, it is a language, designed to be a language, not a crippled toy. The plethora of expression languages is the same thing as the xml -- attempting to find a way to make Java dynamic (which it ain't, and that ain't bad, it just is!).
Now, I said "don't do #{x}" (note, the "#{x}" is not an expression language, it is valid ruby, a very dynamic language) an awful lot, and the examples have been small. So let's sketch a big example, one where tons of arcane "dynamicity through XML" is used: o/r mapping!
Imagine this:
public Customer[] findCustomersByAgeOfParentHobbyAndName(Integer age,
String hobby,
String name) {
Customers customers = this.db.Customers;
Parents parents = customers.joins.Parents;
return this.db.select(customers)
.join(parents).filter(parents.Age.greaterThan(age))
.end()
.filter(customers.Name.equal(name))
.and(customers.Hobby.equal(hobby))
.end()
.execute();
}
Reems of that code is generated, and is makes use of lots of finals and enums (hence direct access to fields). It is however, very bloody safe code. If it compiles, the query is almost guaranteed to be valid. The current issue for real safety is the join and filter, where you could pass something incorrect, but I can see the shape of doing it via generics so that you still get compile safety (it would involve classes like CustomerParentJoin and overloaded join(..) methods for each valid Join type). Yes, the compiler can do all this, and all the peer tables for the database (the join classes, the table classes, etc, can be code generated by examining the schema in JDBC). Each of the arguments passed to the filter(..) is its own type (e.g. ParentAgeGreaterThanCriteria for filter(parents.Age.greaterThan(age)) ), etc. Consider making use of java's lack of dynamicity, it can do nice things for you!
Java has a strong type system (okay, static type system, not strong, or do I have them reversed?) why do we try to force dynamicity into it? I have an answer (hypothesis, really) to that: We think in terms of duck typing, not in strong types, so we make code that matches how we think.
1 writebacks [/src/java] permanent link
Fri, 10 Jun 2005I needed to write something that ran fast, so tried to remember my ocaml. Realized that I didn't remember much, so started just playing. Learned something cool:
#!/usr/bin/env ocaml
let rec fibonacci n =
if n < 2 then 1
else fibonacci (n - 1) + fibonacci (n - 2);;
print_int (fibonacci 10);
print_string "\n"
Does what you want it too:
brianm@kite:~$ ./fibtest.ml
89
brianm@kite:~$
Maybe I need to spend less time with parens and more time with bizarre semicolon rules...
0 writebacks [/src] permanent link
Wed, 08 Jun 2005Ladera was wonderful. I definately recommend it. Now... ESB stuff, filtering through way too much email, catching up with what's happened while I was out, and dealing with "hmm, need some food" not meaning "wander down to unbelievable restaurant overlooking amazing scenery and enjoy."
0 writebacks [/stuff] permanent link
Mon, 30 May 2005Got married yesterday. Wedding was wonderful. Exhausted now. Going someplace beautiful relaxing. Ahhhhh.
Yea!
4 writebacks [/stuff] permanent link
Transparent Persistence, Transient and Detached Objects, and DTO's
Everything I'm going to say applies equally whether you are using OJB's ODMG or OTM layers, JDO (1 or 2), Hibernate, TopLink or someday (hopefully) JSR 220 Persistence. It's about so-called Transparent Persistence. There is a key concept which doesn't seem to be expressed clearly enough in places, so I'll take a stab using slightly different words then are typically used, and probably not make it any more clear =) If you find yourself saying "yes, that is true, but there is this case..." while reading, just keep reading. I am skipping some concepts initially in order to introduce them later. Bear with me, please.
Let's create the idea of a persistence context. A persistence context is like a virtual machine, or a dedicated heap.  It is demarcated space (don't worry how, yet) in which persistence capable objects (to borrow a term from JDO -- basically an object which has been mapped to something in the datastore, and can be persisted) can exist and be related to the datastore. Groups of objects are said to be in the persistence context, though they can certainly exist outside of the persistence context. An given object which is persistence capable, and in fact represents something with the same identity (in the platonic sense) is called an entity. Each entity within a persistence context can be thought of as being bound to the underlying datastore (typically a relational database) to the collection of bits therein represented by the same identity. This is usually simply a row. These are called persistent entities. When a persistent entity has its state change, that same state in the datastore changes (yes, yes, I'll talk about write-behind later).
It is demarcated space (don't worry how, yet) in which persistence capable objects (to borrow a term from JDO -- basically an object which has been mapped to something in the datastore, and can be persisted) can exist and be related to the datastore. Groups of objects are said to be in the persistence context, though they can certainly exist outside of the persistence context. An given object which is persistence capable, and in fact represents something with the same identity (in the platonic sense) is called an entity. Each entity within a persistence context can be thought of as being bound to the underlying datastore (typically a relational database) to the collection of bits therein represented by the same identity. This is usually simply a row. These are called persistent entities. When a persistent entity has its state change, that same state in the datastore changes (yes, yes, I'll talk about write-behind later).
Now, entities can exist outside of a persistence context as well as within a persistence context. When entities exist outside of a persistence context, they are not considered to be bound to the underlying datasource. Generally speaking these entities can be called transient entities.
 That is an imprecise definition of transient, but it is the right one for right now. State changes on these entities are not reflected back to the datastore.
That is an imprecise definition of transient, but it is the right one for right now. State changes on these entities are not reflected back to the datastore.
Now, in all these libraries (I consider them libraries, you call into them in general, rather then have them call into you) there is some central access point for working with persistence contexts. It may be called a EntityManager (JSR 200), a Transaction (ODMG), a Session (Hibernate), or PersistenceManager (JDO). Each one does the same thing. Each instance of the entity manager will have its own conceptual persistence context.
Now, how do objects get into that persistence context, you might ask? The most common way is because the entity manager which owns the persistence context is the one you used to retrieve them. Another way is to tell it to insert a new entity by instantiating a persistence capable object, and telling the entity manager to store it (ie, EntityManager#persist(Object)). Nice, easy.
Okay, lets complicate it some. Every time you call a setter, it would be really craptastic to have to issue a corresponding update to the database immediately. So we introduce the idea of transactions. These are not datasource transactions, though it is a bloody good idea almost all the time to synchronize them with datasource transactions. These are more like units of work. Basically all the changes made to entities in the persistence context are saved up until you tell it to save them out to the datastore (flushing). This is write-behind. It is good, though it does make debugging weird sometimes.
Okay, now once you have write-behind you have some additional states the persistence context needs to keep track of. 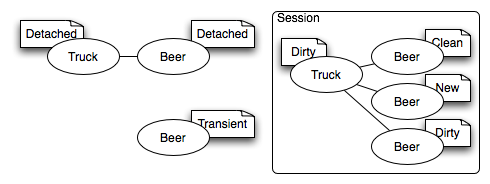 A dirty entity has been changed, but not flushed, a clean entity has not been changed, a deleted entity has been deleted but the delete has not been flush, and a new entity has been inserted, but the insert hasn't happened on the database yet.
A dirty entity has been changed, but not flushed, a clean entity has not been changed, a deleted entity has been deleted but the delete has not been flush, and a new entity has been inserted, but the insert hasn't happened on the database yet.
Just like you have different variations on the persistent state, we need to introduce some similar variations on the transient state. The first is to redefine transient to be a bit more precise. A transient instance lacks identity. It does not represent anything in the database. A variation on a transient instance is a detached instance -- this is an instance which has identity, but is not part of a persistence context. Changes made to detached instances are not reflected in the datastore. There is one last variation, hollow which is what happens when you have a persistence capable object has identity, but no state. It only really crops up in JDO where it is used to avoid all kinds of confusing things that lead to hard to track down bugs in Hibernate (this is not a jab, it is simply true, the hollow state may be good, may be bad -- hibernate gets a lot of use out of its lack of hollow).
Now, people hate staying in the lines, so they like to be able to do things like re-attach detached instances, and do all kinds of bizarre and kinky things with transient objects. Re-attaching a detached instance requires making a detached intance. Some libraries provide a means of explicitely detaching objects, others just do it by default to all persistent entities in a persistence context when the entity manager owning the persistence context closes its connection the datastore. They all (or all will with JDO 2) provide a means of re-attaching, with varying semantics on the details oof how it gets done inside the persistence system. The end result is *mostly* the same.
Okay, back to our way of looking at it as a persistence context. There are explicit ways of passing objects across persistence context boundaries via the entity manager -- inserts and re-attachement being the ways this happens. Now, frequently you attach, or insert, graphs of objects at a time, so when you call the relevent methods on the entity manager, you get the operation applied to the whole graph (or variously subsets of it, as with hibernate's different cascades). All well and good so far.
Let's poke the edges that burn people, using this way of thinking about it.
First, what happens if you have an entity in a persistence context with an object reference to something outside the context when it is flushed? Big fat error. Don't cross persistence context boundaries except through calls to the entity manager. ...
This has been sitting on my HD too long without being finished, so posting incomplete before I head out for honeymoon. Will eventually finish the thought processes, maybe =)
1 writebacks [/src/java] permanent link
Tue, 24 May 2005I've been bitten a number of times in the last several months by there not being a decent CSV library in Java. CSV is just enough of a pain to want a somewhat thought out tool (escaping, quoted fields, possibly comment rows).
So, a simple csv tool that basically mirrors the ruby CSV library ;-) It just has a reader and writer, and usage is (hopefully) dirt easy enough that the docs consist of javadocs and some sample code in test cases:
given a sample CSV file:
Brian McCallister,(302) 994-8629
Eric McCallister,(302) 994-8991
Keith McCallister,(302) 994-8761
You can chunk it up as follows:
public void testExample1() throws Exception
{
CSVReader reader = new SimpleReader();
URL url = this.getClass().getClassLoader().getResource("sample.csv");
InputStream in = url.openStream();
List items = reader.parse(in);
String[] first = (String[]) items.get(0);
assertEquals("Brian McCallister", first[0]);
assertEquals("(302) 994-8629", first[1]);
String[] second = (String[]) items.get(1);
assertEquals("Eric McCallister", second[0]);
assertEquals("(302) 994-8991", second[1]);
String[] third = (String[]) items.get(2);
assertEquals("Keith McCallister", third[0]);
assertEquals("(302) 994-8761", third[1]);
in.close();
}
Or you can use the callback-based streaming api (for big files, for example):
public void testExample2() throws Exception
{
CSVReader reader = new SimpleReader();
URL url = this.getClass().getClassLoader().getResource("sample.csv");
InputStream in = url.openStream();
final int[] count = {0};
reader.parse(in, new ReaderCallback()
{
public void onRow(String[] fields)
{
count[0]++;
switch (count[0])
{
case 1:
assertEquals("Brian McCallister", fields[0]);
assertEquals("(302) 994-8629", fields[1]);
break;
case 2:
assertEquals("Eric McCallister", fields[0]);
assertEquals("(302) 994-8991", fields[1]);
break;
case 3:
assertEquals("Keith McCallister", fields[0]);
assertEquals("(302) 994-8761", fields[1]);
break;
}
}
});
assertEquals(3, count[0]);
in.close();
}
Anyway, is trivially small, but does escaping, quotes, etc correctly -- including escaping for you when you use the writer. Have fun with it! There are no dependencies beyond the JRE standard library.
9 writebacks [/src/java] permanent link
Mon, 23 May 2005My hat is off to the wave of .org millionaires. Hopefully the guys at Gluecode made out enough to qualify for the title, and hopefully the folks working with Simula will in the future =) Bonne chance!
0 writebacks [/tech] permanent link
Fri, 20 May 2005
SeeBeyond Web Site: Total Incompetence =)
So, I need to get some information on SeeBeyond's integration stuff. I go to fill out their "please contact me" form. Hilarity ensues.
First, on the dropdown for What industry is your company? (which is such a wrong question all by itself, "Dude, I am pharma," and is grammatically incorrect aside from being semantically incorrect) try selecting Other. See yourself redirected to their homepage. Oops.
Okay, hit the back button, notice it left it on Other and continue to fill out the form. Submit form. See javascript popup saying Company name is required. No biggie, would be nice for them to highlight the actual field or something, but hey, I'll take it. I fill in company name, resubmit.
URL is required
Fill in url. Re-submit.
How did you hear about SeeBeyond is required
This one is tricky. They have a text field for Other, which I had filled in, but no option in the drop down list for Other. Being annoyed now, I try to figure which of the listed options is the most expensive for the least return, and have trouble deciding between Tradeshow and Industry Analyst -- I go with Tradeshow, I am not sure what the current "independent study" payoff cost is, so I opted to err on the side of the absurd. Really it is a contact who said they might be worth looking at, but he wasn't sure.
I submit.
error '8000ffff'
/scripts/contactSalesForm.asp, line 169
So, while I would love to talk to some SeeBeyond folks about their software, they have effectively DOS'd themselves.
3 writebacks [/src/java] permanent link
Sun, 15 May 2005
Closures: What's the big deal?
Folks get all excited about closures for some reason. If you break away from the closure == anonymous function school, the cool thing about closures is that they let a function have state! To demonstrate, I'll borrow a page from Mr. Dybvig and implement a stack as a function which returns a function, which is passed messages explicitely:
def make_stack(list=[])
lambda do |op, *args|
case
when op == :push
list.push args[0]
when op == :pop
list.pop
else
raise "Illegal Operation"
end
end
end
This snippet defines a function which returns an anonymous function which represents a classical stack data structure. It works:
s = make_stack
s.call :push, "First In"
s.call :push, "First Out"
puts s.call :pop
puts s.call :pop
~>
First Out
First In
The reason this works is because a new list local variable in the make_stack function is created each time make_stack is invoked, and that list is referenced by the Proc returned (created via the lambda call).
This, btw, is easily the basis for a (very) small object system:
def make_instance
vars = {}
lambda do |op, *args|
if op == :define
vars[args[0]] = args[1]
else
vars[op].call args
end
end
end
Okay, this technically cheats a bit because I needed Object to respond to :call, so I added
class Object
# "calling" an object returns itself unless subclass (Proc) overrides
def call(*args)
self
end
end
Now, this is a complete toy, and hack, and is atrocious, but it illustrates the idea, which we then use:
b = make_instance
e = make_instance
b.call :define, :talk, lambda { puts "Hello, world"}
e.call :define, :talk, lambda { puts "Goodbye, world"}
b.call :talk
e.call :talk
b.call :define, :name, "Brian"
puts( b.call :name )
~>
Hello, world
Goodbye, world
Brian
But it gets more fun, we want inheritance, right? Let's make a minor change to make_instance so that it supports prototype based inheritance, and add a new special funtion, new_instance
def make_instance(vars={})
lambda do |op, *args|
if op == :define
vars[args[0]] = args[1]
elsif op == :new_instance
make_instance(vars.clone)
else
vars[op].call args
end
end
end
Now we can build up a "base class" and create new instances which inherit what is defined on the base (like JavaScript):
person = make_instance
person.call :define, :talk, lambda { |message| puts message }
k = person.call :new_instance
k.call :talk, "hello, world!"
Yea closures!
0 writebacks [/src/ruby] permanent link
Thu, 12 May 2005Just found a pointer to XMLStarlet via Tom Moertel. Basically is a command line xml chainsaw -- lots of description, querying, transform, munging, etc capabilities for xml right on the command line, for example:
brianm@kite:~/src/jdbi$ xml sel -t -m 'project/target' \
-v '@name' \
-o ' : ' \
-v '@description' \
-n
./build.xml
compile : Compile all Source Files
compile-tests : Build source for unit tests
jar : Build Jar Library
clean : Remove All Artifacts
test : Run all junit tests
javadoc : Generate API Documentation
release :
site :
brianm@kite:~/src/jdbi$
Which I already received grief on as being easier to do via ant -p -- but the point is to make an example with an xml format folks are very familia with =)
Installable via fink =) Rumor has it that it even works on Windoze!
1 writebacks [/tech] permanent link
Wed, 11 May 2005My mother passed away a few weeks ago. It was unexpected, and at least twenty years too early. I guess there is never a good time for something like this -- though there have been people I've known that suffered up until the end, and for them you are glad the pain is over, even if you will mourn the loss. It just isn't that way here -- it wasn't expected, it wasn't something any of us had prepared for.
I put a lot of balls down (I'd say dropped, but I tried to do it gently) when it happened, and pretty much dropped offline for a while. I've been easing back now, and it's bizarre. I guess major losses count as life changing events, and provide an opportunity to distance yourself and gain some perspective -- the kind you get on your home when you live abroad, but on your life when you go into autopilot.
I don't have much to say (in public) about mourning, or those related topics. There are thoughts that came up which relate to the nebulous conglomerate of ideas I like to think about in public, but even mentioning mom is pushing those boundaries out considerably. So I won't say a whole lot about her.
I'm picking those balls back up now, and looking at the depth of the pile I wonder how I tracked them all. Need to whittle at some of them until they are ready to be passed on, or be set aside -- and I need to pick up a few more once I have some capacity again =)
7 writebacks [/stuff] permanent link
Fri, 06 May 2005Get ready to start using your tinfoil wallets. The American government sticks its head in the sand yet again.
I'm sorry.
1 writebacks [/tech] permanent link
Wed, 27 Apr 2005Downloaded and am reading (only to page 27 so far) the first public draft of the Fortress language spec when LtU posted info about it. Very nice looking stuff. Very Scala like as well.
I'm looking forward to seeing where Sun goes with this. I really like what I see in the spec!
2 writebacks [/src] permanent link
Tue, 26 Apr 2005Released a minor API change version of jDBI last night. Significant features include:
- Global named parameters which may be set on either a DBI or Handle intance. Handles inherit named params from their parent DBI, but names set on the Handle do not percolate back up. This added two methods to public interfaces, so lead to the 1.3.X instead of 1.2.X. Feature request from John Wilson, aka tug.
- Exceptions thrown within the Spring integration system are wrapped in Spring's DataAccessException hierarchy. Thomas Risberg did the heavy lifting for this one (and noticed they needed to do it!). This support will improve with minor releases as I refactor to make things play better with the exception translator.
Global params are easy to show examples of:
public void testParamOnBareFirst() throws Exception
{
handle.getGlobalParameters().put("name", "Robert");
handle.execute("insert into something (id, name) values (:id, :name)",
new Something(1, "Robert"));
Map robbie = handle.first("select * from something where name = :name");
assertNotNull(robbie);
assertEquals(new Integer("1"), robbie.get("id"));
}
public void testOnDBI() throws Exception
{
handle.close();
DBI dbi = new DBI(Tools.CONN_STRING);
dbi.getGlobalParameters().put("name", "Robert");
handle = dbi.open();
handle.execute("insert into something (id, name) values (:id, :name)",
Args.with("id", new Integer(1)));
Map robbie = handle.first("select * from something where name = :name");
assertNotNull(robbie);
assertEquals(new Integer("1"), robbie.get("id"));
}
So have fun with it!
0 writebacks [/src/java/jdbi] permanent link
Fri, 22 Apr 2005
Chatting with Santiago earlier we kicked around some ideas on doing modal webapps in ~pure java. Getting back-button compatible behavior isn't too bad by using a StateRegistry type system and requiring any view state be stored in a registerable component.
Getting linear style scripting is a lot trickier though, let's say we want this flow:
def request_free_icecream()
name = ask_for :name
address = ask_for :address
unless blacklist.check_for_idjits(:name => name, :address => address )
send_icecream_to(name, address)
else
return "rejected"
end
return "accepted"
end
In this case ask_for(symbol) entails a request/response (possibly multiple if validation fails). The flow of what is going on is easy to see. Now, modeling this in a typical webapp might be:
def request_free_icecream()
@session['icecream-request'] = IcyAccumulator.new
end
def set_name
accum = @session['icecream-request']
accum.name @params['name']
end
def set_address
accum = @session['icecream-request']
accum.name @params['address']
finished()
end
def finished
accum = @session['icecream-accumulator']
unless blacklist.check_for_idjits(:name => name, :address => address )
send_icecream_to(accum.name, accum.address)
redirect_to :controller => :globals, :action => :accepted
else
redirect_to :controller => :globals, :action => :rejected
end
@session['icecream-accumulator'] = nil
end
Now, aside from the fact that the second example actually works (unlike the first which is a variety of pseudocode called "ideacode"), it is way harder to follow what is actually happening. Nothing new here, modal webapp proponents have been flogging this horse for years. Now, let's pretend the above code snippets are Java, and as we know we cannot use the standard tool of continuations to build this out, how can we do it?
One option, which Torsten has done, is to transform the code at the bytecode level to emulate continuations. This is the ~classic way, but isn't the only way. It is a bit of a pita to do well, I think (I haven't tried, have just watched people doing it) -- probably because java bytecode doesn't lend itself to CPS style transforms.
What we need to do is effectively transform the first snippet into the second snippet. To do this it needs to be split into the following chunks:
... {
invoke ask_for :name
}
... {
assign result to :name
invoke ask_for :address
}
... {
assign result to :address
unless blacklist.check_for_idjits(:name => name, :address => address )
send_icecream_to(name, address)
else
return "rejected"
end
return "accepted"
}
Which splits the code into the actions in the second code example. Need to be able to match the points at which control flow goes back to the user (ie, send a response and wait) and transform "what comes next" from a thread of execution into a function (functor) which can be invoked, so to look at it again, we would want a transform along the lines of:
one = functor do
name = ask_for :name
end
two = functor do
address = ask_for :address
end
three = functor do
unless blacklist.check_for_idjits(:name => name, :address => address )
send_icecream_to(name, address)
else
#return "rejected"
return_result "rejected"
end
#return "accepted"
return_result "accepted"
end
We now have three functors (some arm waving, bear with me) which encapsulate the flow we described. We will presume "correct closures" as Matz describes them (and groovy implements now, but ruby doesn't yet AFAIK), where the name and address variables are available to the functor being created and assigned to three (right now they'd be undefined in ruby as they are scoped to the box and don't fall through to the outer scope).
Now, we've hit the point where we need to see what ask_for actually looks like. I don't know. It would need to set up a page, fetch the results, and return the request params as an array. Probably it maps the argument to a view of some sort. This is all very cocoon.sendPageAndWait(..)-ish. The key point is that it passes through a single point to ask for a view rendering and announce it wants the results back. You can pinpoint what this chunk of code is.
It is a definable pointcut =)
Now, one of the (few) accepted patterns in AspectJ is a functor transform as I call it, or a worker object creation pattern as Ramnivas calls it. His name is better, but I think in terms of mine anyway (tangent, I am really looking forward to Raminvas's next book!). In this case you need to match the entrance and exit of the flow blocks, which can be nicely demarcated by naming conventions and calls to the "I need a request cycle" function.
It helps if each functor knows its "next", so we can alter it to create:
sequence = functor do
name = ask_for :name
end
sequence = sequence.next = lambda do
address = ask_for :address
end
sequence = sequence.next = lambda do
unless blacklist.check_for_idjits(:name => name, :address => address )
send_icecream_to(name, address)
else
#return "rejected"
return_result "rejected"
end
#return "accepted"
return_result "accepted"
end
Where sequence is the name of our functor, and each one knows its next. There is an awkward bit where the next= receives a proc instead of a functor, this is because it needs to act as a functor generator so that multiple calls to it create new functor instances. Until really implemented, this is just a guess on my part though.
Now, I can see in my head implementing this transform via AspectJ, but it'll take several hours at a minimum to go from rubyesque ideacode to Java/AspectJ implementation, so I am going to put that off. Pretend we have it, and have a useful Continuable implementation which is the functor stuff in the ideacode. Heck, the transform to a worker object may be viciously hard in this case, is just idea stuff right now.
We need to store these continuables in the session, probably under a map just like the continuations in FlowScript, and be able to call back to them based on continuation ids, we would need some convenient mechanism for managing them. That is a worry for another day -- right now we will treat it like naive C memory management (ie, none -- don't let sessions live long). Probably a sweeper-like system will make the most sense, but that is just intuition.
What we kinda did was kinda described a kinda implementation of a (broken and very limited) form of the continuation passing transform via aspects.
1 writebacks [/src] permanent link
Thu, 14 Apr 2005
Prelude> 1.1 * 2.2
2.4200000000000004
Prelude>
13 writebacks [/src/haskell] permanent link
Tue, 12 Apr 2005Some guidelines when building web applications.
-
Seperate view and model state.
Model state is the stuff associated with the problem domain. If your application is a fancy bug tracker, then the model state is bug statuses, notes, workflow states, transition histories, etc. View state is the current sort order for a list of bugs, the preferred number of bugs on a screen, the logged in user id, the alerting rules, etc.
There is also persistent view state -- the "where someone visited" log, the preferred home page, a set of filters to be applied by default. This is stuff which usually makes sense to stick in the database. This should not be managed the same way as the model state. Typically the persistence requirements are very different for view state, so different that you will probably want to use a different persistence mechanism. This is okay. Really, it is.
Of the frameworks I've used, Tapestry makes the distinction between view and model state the easiest to see. View state is stored as component properties, model state is... part of the model. The next Tapestry is adding even better support for how vie state is managed. I'm looking forward to plugging in database (with good caching) backed properties, for instance, so that for a given user the property is quite fixed.
-
Manage view state like manually managed memory.
If view state is seperate from model state, we need to figure out how to manage it. Most often it is plunked into the session abstraction (
HttpServletSessionin Java Servlets, for example). This is great, it is what the session is for. On the other hand, most often it is treated like a novice's C or C++ heap -- it leaks, terribly.Until modal webapps catch on in a bigger way, we cannot make use of the stack for managing this memory -- we need to be disciplined about memory management. The easiest way is the good old "if you allocate it, you destroy it" technique. This works well for simple things, like wizard style multi-page forms, but can get more complicated for other bits. Implementing a reference counting mechanism isn't difficult (if a component cares about it, increment the count, if the component no longer care, decrement, have a servlet filter do the GC on the session after each request) though it feels awkward to work with when you have GC in most languages nowadays.
-
Never change model state with an HTTP GET.
This is a strong suggestion in HTTP, and a bloody good one. Any complex interface component (be it a Tapestry, JSF, Wee, Seaside, or Rails component, a tag library, or whatever Zope calls em) will need to interract with the user internally -- if just to handle sorting of a table or some such. This requires being able to get back to the place it was without changing anything. This is GET.
There are lots of other good reasons for not allowing model state to change with a GET -- HTTP proxies, caches, browser caches, back buttons, spiders, replay attacks, bookmarks... the list goes on. Changing model state with a GET is bad. Don't do it.
The jury is still out with view state. The purist in mean says no, the pragmatist is beating that purist with a lead pipe though.
-
Treat system tests like an alternate user interface.
There are lots of levels of automated testing. Uint tests, integration tests, system tests, etc, etc. System tests for the application layer (ie, where the model state and business logic is implemented) should be treated as an alternate user interface. That is, they should not use any artifacts from the view. This doesn't mean they shouldn't rely on the
javax.servlet.*artifacts (they shouldn't but that is a different beast altogether), they shouldn't rely on the web actions (or pages, or components, or controllers, or whatever you call them in your tool of choice), the view components, the view level interfaces and classes, etc.All the business logic and state should be programmatically accessible without duplicating logic from the view components. It is tough to get this right without simultaneously developing multiple interfaces. Treating the system tests as that alternate interface does a couple things. One, they are fantastic integration tests for the actual business core. Two, they are that second interface that lets you accurately gauge what code belongs where. Win, win.
- View complexity is usually higher than model complexity.
The user interface is usually much more complex then the business logic. On the other hand we usually spend much more time hammering out a correct model for the core then we do modeling the user interface (code, not look and feel). Unless you are writing a simulation, complex forecasting tools, a massive routing system (which have simulations in their dark and twisted hearts), air traffic control (which have simulations in their dark and twisted hearts), or something else with a simulation in its dark and twisted heart... chances are that you "business logic" is nothing more than a reporting system with very little behavior about the stuff stashed in the database (or filesystem, or whatever).
Recognize that the user interface complexity is usually an order of magnitude more complex then the complexity in the problem domain. Don't brush it under the carpet in favor of getting a perfect model of the problem domain. Usually modeling the business problem is, in fact, much easier than modeling the sophistication that eventually gets kludged into the interface facing the humans.
2 writebacks [/src] permanent link
Mon, 11 Apr 2005I've been pondering monads and suddenly the lightbulb goes off. I cannot explain better than LtU does so I won't try. Need to fire up ghci when I have a chance and see if my lightbulb is right.
Drives home that language != syntax.
0 writebacks [/src/haskell] permanent link
Fri, 08 Apr 2005
Kragen captures so much truth...
0 writebacks [/tech] permanent link
Thu, 07 Apr 2005Matt and Dion already spilled the beans, so here's the chili: a bunch of stuff to make using Lucene from Spring more convenient:
public void testDemonstration() throws Exception
{
LuceneTemplate lucene = (LuceneTemplate) beans.getBean("lucene");
Document one = new Document();
one.add(Field.Text("name", "Brian McCallister"));
Document two = new Document();
two.add(Field.Text("name", "Eric McCallister"));
lucene.addDocuments(new Document[] {one, two});
Document[] results = lucene.searchForDocuments(lucene.parseQuery("Eric", "name"));
assertEquals(1, results.length);
assertEquals("Eric McCallister", results[0].get("name"));
}
There are other convenience methods, callback handlers for readers, writers, and searchers which managed opening/closing, etc on the LuceneTemplate, and factory beans for direct access to components without going through the template, but that is a nice example. The Spring config used for this test is:
<beans>
<bean id="directory" class="org.skife.spring.lucene.RAMDirectoryBean"/>
<!-- <bean id="directory" class="org.skife.spring.lucene.FSDirectoryBean"> -->
<!-- <property name="location"><value>/tmp</value></property> -->
<!-- </bean> -->
<bean id="analyzer" class="org.apache.lucene.analysis.standard.StandardAnalyzer"/>
<bean id="template" class="org.skife.spring.lucene.LuceneTemplate">
<property name="directory"><ref bean="directory"/></property>
<property name="analyzer"><ref bean="analyzer"/></property>
</bean>
</beans>
The fun part is that the components work with Spring transactions (via readers and writers LuceneUtils, which the template uses as well), so that if you index documents inside a transaction, then roll it back, they aren't added. Ditto removing docs, etc. This is awfully handy if you do things like handle document indexing via an interceptor on your DAO ;-)
Haven't figured out where the code will be hosted, yet. There isn't much. I've offered it to the Spring folks, and have had Spring Modules suggested, but haven't thought hard about anything.
So until then, you can grab the jar (only dependencies are Spring and Lucene) and sources from me, and see the API docs. My apologies for not having a source download -- it was developed as part of another project, and the build and sources are all in there (and I'm too lazy to split out a seperate project since I hope to host it somewhere else =). Until it finds a home, I'll keep pushing stuff to the aforementioned links as I make significant changes.
3 writebacks [/src/java] permanent link
Wed, 06 Apr 2005If you find yourself doing a lot of eval(..) based metaprogramming, remember to include debug stuff!
begin
eval("dsadh!!sadkhj how are you today?")
rescue Exception => e
log.error "Metaprogramming error [#{e}]"
end
Which is nifty and all if the eval fails, but what happens on the way more subtle?
begin
eval <<-EOM
def foo
robert is sick today
end
EOM
rescue Exception => e
log.error "Metaprogramming error [#{e}]"
end
Where you don't get the syntax problem until you invoke foo. Solution!
eval <<-EOM
def foo
begin
robert is sick today
rescue Exception => e
puts "Error while invoking foo defined from [insert stuff to help you debug]: \#{e}"
end
end
EOM
You cannot catch syntax errors, but because so much of ruby uses ruby this isn't a big deal most of the time =) Note escaping the hash in \#{e} -- this is important because just #{e} would fail. Why is an exercise left to the reader ;-)
4 writebacks [/src/ruby] permanent link
Just need to convince O'Reilly to actually publish it...
0 writebacks [/src/lisp] permanent link
Mon, 04 Apr 2005Justin Gehtland posted some loose macro benchmarks for an app he's done in both Rails and J2EE. The performance numbers were interesting, if just in that without caching they performed about the same. Yawn, yawn -- perl folks have been saying this for years. When the heavy lifting is done in C (web server, database), and the app logic is in a scripting language (the, er, app specific stuff), you get the best of both worlds.
Now, where it does get interesting is when he turns caching on. Enabling caching on the rails version jumped requests per second from ~70 to ~1750. The same on the J2EE side from ~70 to ~80. Now, there are a ton of explanations for this, ranging from Servlets being theoretically unable to scale as high as a select based web server in C, to Justin having set up caching better on the Rails side of things, to the caching mechanisms employed on the different stacks.
All of these probably play in, though I think the theoretical limit one is pretty bogus, so will discard it as rubbish (you can break the servlet spec in a transparent-to-the-programmer way and use NIO to get way better throughput). The other two, on the other hand, are very relevant.
Caching being better configured on the Rails impl is easy to explain -- caching is dirt easy to configure in rails. It's a one-liner in the controller. To clean up after the cache is also dirt easy, you attach a sweeper which is basically a callback that picks up on when a cached element should be discarded. This does two things, 1) it lets you enable caching as a seperate concern from the logic/view very, very easily, and 2) lets you cache aggressivley as clearing out the cache is easy to configure. The equivalent in J2EE space is much tricker. Cocoon probably has the nicest cache setup, in terms of making it easy to cache things, but it lacks the easy cache invallidation. The much more commonly used OSCache is really easy to use, but litters your JSP's with caching stuff, and invalidation, again, is much trickier. There are a bunch of other ones, but I don't know of one as easy to use.
The other point is the caching mechanism. The Java-only route still generally has a higher overhead to throw cached data at the client in comparison to Apache or lighttpd shoving static content at the client -- which rails page caching basically does. You can get this with the Java stack -- it is one of the reasons people give for putting Apache Web Server in front of the servlet container, but it is much nastier to cache semi-dynamic stuff via mod_cache on a different server, communicating via headers, then it is to do it via the page and sweeper mechanism in rails.
It reminds me, a great deal, of a conversation I had with a really bright guy who re-implemented (okay, actually pre-implemented, or co-implemented) something very popular in the open source world (written in C) in ocaml. After beating on it for a while he concluded that the basis for the whole design was broken, but he attributes being able to see why the whole design was broken to the expressiveness of the language, not to any abstract conceptual model. The C version is in widespread use, releases bug fix versions quite frequently, and a lot of people wonder if it will ever actually be stable.
Whether he was right or not, in this case, is a guessing game. He has a PhD in this stuff, I just use it. His arguments seemed quite valid, and the tangent of noticing design flaws because the language got out of his way (to paraphrase him into PragDave's description of Ruby) is what really stuck with me. The caching stuff Justin found is in the same vein. Getting the massive performance boost out of rails from caching is easier to do because it is easy to see what is being done. The framework is expressive. The same can very easily be said of ocaml compared to C. It is an argument that has come up again, and again, and again, (and again) in discussing the relative merits of Java, and C, and assembly languages, and Fortran, and Python, and Perl, and Ruby (oh my!). Language matters. Expressiveness matters.
I think most people would agree that algorithm selection matters more than language of implementation for performance. That is what this is. The simple fact is that Justin could get a 20x speed improvement with the ruby based implementation, not because ruby is faster (it definately isn't) but because the language, the framework, and the stack makes it easier to do what he wants to do. The theoretical limit of optimization is definately in J2EE's favor, but if actually doing those optimizations is significantly more difficult (complexity for the most part) -- does it matter if they can be done?
The other interesting thing here is that the boost rails can get from caching is directly tied to it being closer to the metal. Rails caching is basically "not caching" but generating static content and letting the web server spew it out. Java based caching is almost always at a much higher level of abstraction -- specifically to make it more flexible. OSCache, for example, lets you cache arbitrary fragments of JSP's and uses a servlet filter to fill in the blanks from the cache when the cached version is used. Rails doesn't do this. It has different levels of caching, but it loses some flexibility in order to make it easier to use and take advantage of the services otherwise available from the web server (in the case of page caching, anyway). The tradeoffs are interesting, and are the anture of design.
Another good place to see this kind of tradeoff is in SpringMVC. Most web frameworks build their abstractions around "physical" elements: actions, pages, requests, etc. A lot of the SpringMVC stuff builds abstractions around "behavioral" elements like wizards. You see this all over Spring, in fact, not just in SpringMVC. I think Rod et. al. are closet FP junkies. These are underlying design assumptions and ideas. Sure, it has actions, and requests, and the standard structural abstractions. The interesting bits are where it goes beyond that and into the behavioral abstractions.
Okay, am rambling now, gonna shut up =)
1 writebacks [/src] permanent link
Andris Birkmanis posted a reference to a paper, by David Teller, on resource recovery in pi-calculus on LtU. I'd not really thought of dead process collection in terms of garbage collection before, but it certainly makes sense when thought about.
This is also something to think about with the growing interest/importance of modal web applications (continuation based a la Wee, Seaside, RIFE, Cocooon Flow) which effectively model a session as a continuable process. I'm wandering away from David's paper, but how to handle the growing memory requirements of a bunch of continuations in the session gets hairy. Cocoon does it, thinking in terms of GC, via explicit "memory" management, where continuations are stored in a tree structure and you are responsible for invalidating them yourself. Not sure if there is an equivalent for "dead back button detection" as there is for dead process detection.
Ah well, food for thought after I've had some more coffee.
3 writebacks [/src] permanent link
Sun, 03 Apr 2005I am quite sad that I was unable to drop in on PyCon this year, it being all of a couple hours away, but the timing was awful. On the other hand, Mark Watson pointed out that the papers are largely available for download!
0 writebacks [/src/python] permanent link
I've been thinking about process a lot lately. I sort of think of process like I think about the police. I really like having the police around, as long as they are not around me. My old saw has been "when a company starts worrying about process it is because it no longer trusts its people." I'll stand by that, for the most part. I've been known to say that a process committee is a sign of a human resources issue. This is all tongue in cheek, of course, but...
All of that said, a repeatable, optimized process is a crucial thing to have (like the police). In a utopia you wouldn't need the police. Can you think of a company you've worked at that could be called a utopia? Exactly.
I've done XP (and actually done it, all the elements) and I've done N(ot)XP (some of the steps, and call it XP), something calling itself RUP, something calling itself Spiral, and like everyone else in the industry lots of waterfall. XP is interesting as the early poster child (and now flame target) of the agile movement. I like a lot of the verbiage coming out of the agile movement. It is the kind of thing saying "don't make an eight lane superhighway and expect people to go 45 because the signs say that, duh" to software development (and use police to enforce the 45).
If process has a place, and in fact is needed, how the heck do you do this? I admit, I am deeply scarred by having been involved with CMM certification. CMM is... a nice opportunity for management consultants to make some more money. You trade predictability for productivity in a directly inverse proportional relationship. The idea is sound, but I think the design is wrong (okay you SEI guys, start the flamethrowers). No, I don't have a wholly better one, but people like Mary Poppendieck at least make sense.
I've been with product companies most of my career, and most recently with an ASP model. Typical feature request turnaround time was a couple of days there. It was pretty cool. Prior to that I was with a big waterfall process company, with year+ development efforts for a single version. Typical feature turnaround there was closer to the limit of 1/n as n approaches 0.
These two most recent product companies provide a stark contrast with each other, which colors my view a great deal. Iterative design and development works. Keeping iterations small, automating the heck out of everything (making that automation important), and delaying decisions works. In my experience anyway.
So, I am a consultant now, and things change. It's really interesting how my outlook changed. Previously the company's culture, team makeups, etc, were known qualities. I trusted my coworkers' judgement and ability because I knew it. Now I fully trust the abilities of my coworkers, but I cannot know the abilities of the people who will be maintaining code I work on, as they won't be my coworkers. This kind of changes my perceptions, a lot. My natural tendancy is to presume most people are smarter and more capable than me. For the most part, this is true. But, it is also scary as the long term viability of a product you are instrumental in designing and developing is sure as heck going to reflect on you (and by you, I mean me, and the consultancy I work for), so I am sure as heck motivated to make it unbreakable.
Oracle flirted with "unbreakable." I wish their installer was unbreakable (or at least allowed for specifying a bloody ip/hostname instead of trying to guess it when the machine is dhcp'd, or has multiple interfaces (and en1 is active, not en0) -- yes, I will update /etc/hosts when my ip changes, but I want oracle on my laptop, darn it). I digress.
So I start worrying about process from a defensive posture. All of a sudden I don't trust the people, because I have no clue who "the people" are, and cannot know. This makes me feel really, really bad. I suspect "the people" are smarter and more capable than I am, but I don't know, and cannot know. I think this is why bigger organizations worry more about process. It is easy to trust "the people" when there are only twenty of them slinging code, but when there are 500 it is impossible to know them.
So, no answers, but am poking around, and a whole bunch of folks are poking around at this stuff in a big way, and seem way brighter and more capable than me =)
0 writebacks [/tech] permanent link
Thu, 31 Mar 2005
Things I wish I had time to do...
Need to start writing these down again so that I can refer back when I have some spare time.
- Pass-through caching for ActiveRecord
- Ruby bindings to ActiveMQ and/or JORAM
- Scoped containers for SpringMVC
- Learn Haskell
- Implement a reasonable, non-xml, dsl for messaging systems which can replace flowchart oriented programming
- Take over the world (and next weekend, learn French)
Ah well, spare time, how I miss thee. If you ever wonder why lots of the most interesting stuff is coming out of Benelux, Scandinavia, and Germany, consider the amount of work time vs vacation time therein.
5 writebacks [/src] permanent link
Wed, 30 Mar 2005I guessed right! Core Data (scroll down) uses an SQLite backend =) Anyway, looks very interesting, and I like how it is retargetable for different backends, presumably transparently. The whole Objective-C thing is kind of annoying, though. Wish they'd standardize on a higher level language for app development, at least something with real garbage collection, if not a scripting language (PyObjC is pretty nice, I hear).
4 writebacks [/tech] permanent link
Mon, 28 Mar 2005Three of my talks were accepted for ApacheCon Europe! Woo hoo! I'll be speaking on Managing Open Source, an Introduction to Rules Engines using Drools, and Cheap, Fast, and Good: You can have it all with Ruby on Rails.
The schedule isn't up, but the times and days are attached to sessions, reachable via the speaker list, so you can figure it out if you try hard. It looks like a great session lineup, and a lot of good (the ones I have heard before) speakers, and promising topics from people I haven't.
I've never been to Germany and dont know much German. This'll be fun =)
1 writebacks [/src/apache] permanent link
Sat, 26 Mar 2005
Quantum Revision Control, d00d!
Forget relational algebra being the trump card, we've got something better now! (emphasis mine)
Darcs is a revision control system. Darcs is simple to learn and use, with a powerful new approach to meet the needs of today's distributed software projects. Darcs is decentralized, based on a "theory of patches" with roots in quantum mechanics.
I expected darcs to be either vastly amusing or awesome. Someone whipped out the Einstein disprover on the "my technology is cooler than yours because of maths" (physics now!). =)
Playing some, I like it thus far. Not ready to switch from my subversion-by-default policy, but going to work with it some more! Functional weenies make all the cool toys, maybe it's time to learn haskell after all.
0 writebacks [/tech] permanent link
Tom wrote a mini-interpreter for ruby in haskell... in order to understand ruby's calling semantic better while learning the language.
Tom wins.
0 writebacks [/src/ruby] permanent link
Thu, 24 Mar 2005
The generic installer (AIX download) for Weblogic 8.1 sp4 (platform) installs cleanly from the java installer. Download the jar, double click the jar, go through the install wizard. Breath sigh of relief. Now if only Oracle would fix their root.sh script to use /usr/bin/env [command] instead of hardcoding incorrect paths...
Yea!
0 writebacks [/src/java] permanent link
Wed, 23 Mar 2005
Open Source in the Corporate World: Eben Moglen's Keynote
The opening keynote was by Eben Moglen. I have to admit I was worried at the beginning when he started the Free Software propaganda, but he is a powerful speaker. He took a lot of the perceived venom out of the GPL and the FSF stance, and cleared a lot of the confusion. I came away almost considering the GPL to not be t3h d3v1l. He's pretty good =)
From a more practical point of view, I was able to talk with him afterwards about the LGPL and Java FUD that is floating around. His take is that the LGPL works fine for Java as worded, though he'd be open to changing the wording when they look into the LGPL (after the GPL 3), if someone could come up with something to make it more clear. He talked about looking at it from a copyright law point of view more than a "what is linking" point of view. While a jar is definately not a header file, the concepts of a combined work and derived work are copyright concepts (this is me interpreting what he said, not what he said). It is pretty clear to a practitioner what is a combined work in Java and what is a derivitive work, so what is the big deal?
Sadly, the room for confusion and air of confusion is enough to create trouble. Perception matters a lot =(
0 writebacks [/tech] permanent link
Sun, 20 Mar 2005When I juggled a bunch of settings on my blog a while back I broke writebacks! I wondered why people stopped commenting altogether. Maybe it is time to go ahead and post my email somewhere so people can let me know...
0 writebacks [/stuff] permanent link
I love Ruby, and quite like RoR, that's pretty well known =) The flavor of a lot of the hype annoys me (though less than it does my friend Geert), as one of the things I have liked for the last several years is the openness and pragmatism of the Ruby community. I think a lot of the bad attitudes we're seeing related to Rails, and Java bashing in that community, come from the PHP community, more than the Ruby community. It sounds like the noise the PHP community has been making for years, and if you poke at it, it seems it is even a good number of the same folks!
A lot of folks in the Java tribe see Rails as an assault against Java, but there is another group who are having a similar reaction, and that is the PHP community. An awfully lot of prominent Railsers stepped in from the PHP side of the fence, rather than the Java side. This includes David himself, who had left the Java camp for the PHP camp a while back.
An interesting way to view this is looking at platforms instead languages or frameworks,  and see the Rail craze as the intersection point where a disruptive technology (LAMP) starts biting into the market of the dominant product (Java). To borrow a graph from Clayton Christiansen, what has been the world of PHP and LAMP, which provides low-end dynamic sites and applications to people who would not otherwise be served by the dominant technology (Java), or for whom Java way overshoots requirements.
and see the Rail craze as the intersection point where a disruptive technology (LAMP) starts biting into the market of the dominant product (Java). To borrow a graph from Clayton Christiansen, what has been the world of PHP and LAMP, which provides low-end dynamic sites and applications to people who would not otherwise be served by the dominant technology (Java), or for whom Java way overshoots requirements.
In the past, the market served by LAMP has been of little interest to mainstream Java developers -- as Dain puts its, the market for $10,000,000 applications is much more interesting than $10,000 applications. Java developers have been chasing the needs of their best customers, the people with $10,000,000 projects, and doing a fantastic job of it. The bottom of the market is better served by simpler, more agile systems, however.
Mr. Christiansen pointed out, years ago, that the rate of improvement for the disruptive technology eventually pushes it up-market enough that it competes, and usually supplants the dominant players. The best example here is the old PC and minicomputer story, which we are all very familiar with. Minicomputers still serve the high end market they narrowed their aim on, but they are fringe, not the dominant player.
Ruby on Rails, solves an identical problem as PHP -- it provides a very rapid, very inexpensive to develop and deploy, optimized for the common cases, solution for internet application development. It specifically ignores the big-ticket items (XA, MQ, etc) which big Java solutions are optimized for dealing with (because this is what the best customers have needed).
Interestingly, this anology only holds up when it is viewed as an extension of LAMP. It isn't, really, as right now setting up a solid Rails deployment platform is almost as complicated as setting up a Java one. Rails under CGI is a joke, you really want FastCGI to set this up, and setting up FastCGI is easy for folks with systems admin experience, but quite a stretch for the typical PHP developer who relies on the ISP or hosting company to keep Apache and PHP properly configured. On the other hand, it does work under CGI, if with degraded performance, and reasonably priced hosting optimized for Rails is easy to find -- and is priced more in line with more common PHP priced hosting than typical Java hosting. I think the anology works, personally.
Rails may represent the point where LAMP starts biting into the markets mostly served by Java. I doubt it has yet, in terms of contracts and dollars, but the people who do the work on those contracts, and make those dollars, are paying attention, and are impressed by what they are seeing. It is a short jump to seeing the lower end of the Java-served market (single database, web interface only (including SOAP and REST)) market get sucked out. Java will still be best served by playing to the needs of the high end. There is a ton of money to be made there. The low-end is starting to having it belly ripped open, and the blood is in the water, as RoR makes headway into the Java market.
Heck, even calling it a Java market isn't accurate. The market is "customers needing highly integrated, complex, multi-interface applications tailored to their specific needs." The tools aimed at the "customers need web applications tailored to their specific needs" are cutting into the first. Rails (not Ruby) is the tool which is plunging the deepest right now, but PHP, Python based tools (Zope etc), and Perl (the grandaddy of it all (as the father of Ruby (mated to Smalltalk) and Python (mated to, er, Guido), and PHP (mated to the Apache Web Server))). Rails isn't a Ruby framework, so much as a FLAPR (FreeBSD, lighttpd or Apache, PostgreSQL, Ruby) (Flapper!) framework. I think that model of thinking about Rails is valid.
The other thesis this is predicated upon is that you can model development tools using theories designed to model business and markets. You'll have to judge that on your own. I haven't done the formal research to find the facts, that would support this idea, but it feels right with what I have seen, and fits the theories well =)
2 writebacks [/src/ruby] permanent link
Thu, 17 Mar 2005For JavaOne '04 I submitted 0 proposals and presented in 2 sessions. JavaOne '05 I submitted three proposals and will be presenting 0 of them. At least I am in good company. One of them lasted until this morning, so it must have at least been in the running. Interestingly, the one that lasted the longest was probably the least important or relevant, although it was also on the least politically sensitive subject.
Which one do you think lasted the longest, (1) understanding the business side of open source (risks, maximizing investments, hr considerations -- presented as a business case and in terms of business concerns more than technical (we've all seen the technical side until we've turned blue)), (2) making informed decisions about approaches to relational persistence (promising to even examine where EJB 2.1 entity beans are the best choice!), or (3) practical applications of rules engines (from short case studies)?
(1) risked wandering afield from Java, so that being turned down wasn't a big surprise. (2) is way too touchy a topic right now, especially as I can be perceived as being partisan (I am on the JDO 2.0 expert group (but that is because I was convinced to do so after spending a few beers arguing with Dion about why I really disliked JDO 1.0)), (3) is a growing technology which is becoming much more prevalent and, like AOP, is exceptionally powerful both conceptually and in practice, but which most people don't know how to use in reasonable ways (yet!).
That said, I'm not especially bothered by this. Sure, you want your proposal accepted as an ego thing, but really that was about it for me and JavaOne. I care about the subjects I proposed to talk about, quite a bit, but the type of talk you do for JavaOne is not nearly as interesting as the type of talk you do for other conferences. The size of each session, even the BOF's, is too big to get any kind of real interaction going, and the mix of attendees makes it really tough to do anything but a very general or lightweight treatment of a topic. The tradeoff is that you can reach a larger audience, and a more varied audience in one go -- the same as the drawbacks. I like meaty technical things, myself, which is tough in that setting.
ApacheCon Europe is a whole other story, though. I care about that conference =)
0 writebacks [/tech] permanent link
Mark Watson timefully pointed out a helpful binary distro of gcj for OS X! Nice as I am using it for ruby Lucene bindings =)
0 writebacks [/src/ruby] permanent link
Tue, 15 Mar 2005jDBI is a thin wrapper around JDBC, designed to be convenient for the programmer instead of whatever JDBC was designed to be conveninent for =) It uses the Java collections framework for query results, provides a convenient means of externalizing sql statements, and provides named parameter support for any database being used, hooks into the various transaction systems (local, BMT, CMT, Spring, etc), and is hopefully useful.
All 1.2.5 does is use the batch api for handling scripts. This allows for DDL in scripts, which is kinda handy, as a lot of databases don't allow DDL in prepared statements (which the default jDBI statement execution uses).
Go have fun with it!
Coming soon: using the externalized SQL system for scripts instead of the current specialized script handler.
0 writebacks [/src/java/jdbi] permanent link
Mon, 14 Mar 2005
What the heck, another useful little script. This one is called svnrepo which does the simple thing of providing convenient svn repository munging:
#!/usr/bin/env ruby
entries = File.open("#{ENV['PWD']}/.svn/entries")
begin
escape = callcc do |escape|
entries.each_line do |line|
if line =~ /\s+url="(.+)"/
repo = $1
if ARGV.length > 0
arg = ARGV[0]
arg = arg[1, arg.length].to_i
repo = repo.reverse
arg.times do |i|
repo = repo[repo.index("/") + 1 , repo.length]
end
puts repo.reverse
else
puts repo
end
escape.call
end
end
end
rescue
puts "You backed up too far into the repo string"
exit -1
ensure
entries.close
end
The reason for this instead of just svn info | grep URL | cut -f 2 -d ' ' is backing up directories in the svn repo (svnrepo -1 or svnrepo -2 to back up one directory, or two, respectively):
brianm@kite:~/src/jdbi$ svnrepo
svn+ssh://jdbi.codehaus.org/home/projects/jdbi/scm/trunk
brianm@kite:~/src/jdbi$ svnrepo -2
svn+ssh://jdbi.codehaus.org/home/projects/jdbi
brianm@kite:~/src/jdbi$
so you can do niceties like the tag-release.sh script:
svn cp $(svnrepo) $(svnrepo -1)/tags/release-$(date +%Y-%m-%d)
It also has a fun gratuitous use of a continuation as a premature optimization ;-)
1 writebacks [/src/ruby] permanent link
Sat, 12 Mar 2005An unnamed JavaBlogger posted about his JavaBlogs pre-processor, so I figured I'd post about my bloglines monitoring script:
#!/usr/bin/env ruby
require 'net/http'
require 'rexml/document'
require 'stringio'
LOGIN = 'bloglines_account@example.com'
PASS = 's3kr3t_bl0gl1n3s_p4ssw0rd'
Net::HTTP.start('rpc.bloglines.com') do |http|
request = Net::HTTP::Get.new('/getitems?s=0&n=0')
request.basic_auth LOGIN, PASS
response = http.request(request)
REXML::Document.new(response.body).elements.each('//channel') do |channel|
puts "#{channel.elements['title'].text}"
channel.each_element('item') do |item|
puts " #{item.elements['title'].text}"
end
end
end
Which just does a nicely formatted title-by-blog listing of your unread stuff on bloglines. Combined with GeekTool it's pretty handy =)
3 writebacks [/src/ruby] permanent link
Fri, 11 Mar 2005Was chatting with Robert this morning about old code, and stuff that you've written that makes you wince now.
Wincing at your old code is good. It means you have learned a lot since you wrote it =) Only when you have hit a plateau will you look back at your old code and nod approvingly.
Maybe this is a good test for the classic "year's experience" problem. If your code is a year old, and looking at it now you'd do it exactly the same way, you just relived a year and it doesn't count.
0 writebacks [/src] permanent link
Wed, 09 Mar 2005
So, what does it mean if a guy links to a girl?
Using Shelley's analysis, all kinds of things ;-)
0 writebacks [/stuff] permanent link
Ruby Central 2005 Codefest Grant!
Don Coleman and I were granted our codefest grant to create ruby bindings to Lucene! Rockin. I have to admit that we didn't ask for much of a grant, just enough for "hackathon room beverages" ;-)
1 writebacks [/src/ruby] permanent link
Tue, 08 Mar 2005I have mentioned before, in Scoped State, that I think NanoWar got the containers in webapps things right. I've been thinking about it more now, and there is something I want that I cannot do yet.
NanoWar works by having a hierarchy of containers, one at the application scope, one in each session whose parent is the application container, and one is created for each request with the parent as the appropriate session container.
This model allows for stateful components in the meaningful scopes -- if you have session state, it is stored in a component scoped to the session. Actions can be stored at any level -- stateless ones (a la Struts or SpringMVC) may be defined in the application level scope, one-off actions (a la WebWork) can be defined in the request scope container. Wizard style ones (if you don't have a concept of wizard scope) can be session scoped, and use a state machine to figure out what is next.
Where this falls apart, however, is that you can only traverse down the hierarchy. A component in the session container can see components in the application container, but not the request container. Components in the application container cannot see any other scopes. If you think about components as state holders this scoping makes sense. There is even an idiommatic workaround where, say, a request scope action would pass a session scope component as an argument to a call on an application scope service. Here it is, a bit more clearly:
# Defined in Request Container
class JobController
inject :current_user
inject :job_dao
def list_jobs
return job_dao.find_active_jobs_for(current_user)
end
end
#Stored in Session Container under :current_user
class User
attr_accessor :name, :id
end
#Stored in Application Container under :job_dao
class JobDao
def find_active_jobs_for(user)
... return jobs from somewhere ...
end
end
Forgive the ruby-esque pseudo-code when talking about Java stuff, it just makes for clearer code. The inject :component_id basically handles the dependency injection bits. We have a singleton dao, a "session singleton" current user (ie, only one ever for a given application session), and the current request scoped action (JobController). The action passes the session scope component to the application scope component. Perfectly reasonable in this use case.
Let's look at an alternate design though, which may be less reasonable in this particular case, but much more so in some examples we'll look at after we express the idea. Let's give the container a concept of a scope. The current crop all have this in very limited form now, where the scope is either "global" or "per request for it" (ie, singleton or not). Let's define contexts within the container, and allow components to reference across those contexts:
beans:
context:
id: application
bean:
id: job_dao
class: JobDao
autowire: true
bean:
id: user_dao
class: UserDao
autowire: true
context:
id: session
bean:
id: current_user
class: User
autowire: true
context:
id: request
bean:
id: job_controller
class: JobController
autowire: true
Now, all these components can be aware of each other, but across context boundaries only via proxies, as any given call to one must be in (from?) a given context, so you can have multiple instances of a context
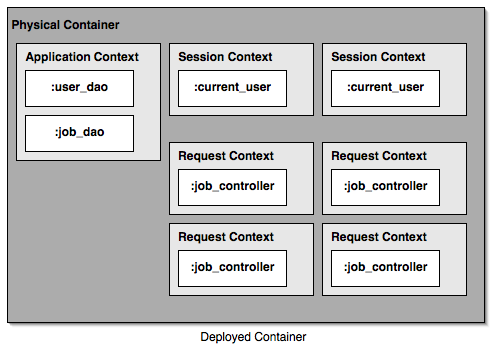
So we could rework the components earlier defined to have the dependencies like:
# Defined in Request Context
class JobController
inject :job_dao
def list_jobs
return job_dao.find_active_jobs_for(current_user)
end
end
#Stored in Session Context under :current_user
class User
attr_accessor :name, :id
end
#Stored in Application Context under :job_dao
class JobDao
inject :current_user
def find_active_jobs_for(user)
... return jobs from somewhere using current_user ...
end
end
The list_jobs call is made with three specific contexts, a given request context, a given session context, and a given application context. The JobDao has a proxy to the current_user component, which will always evaluate to the one in the current context.
Now, for the case here, listing active jobs for a user who happens to be the currently logged in user, this doesn't buy us a whole lot in exchange for complexity in the container.
So, here is a better example which focuses on a pretty common requirement:
# Stored in Application Context
def class UserDao
inject :current_user
inject :dbi
def find_user(criteria)
return dbi.open |h|
users = h.query "select * from users where #{criteria} " +
"and (manager_id = :user or user_id = :user)",
{:user => current_user.id}
return results_to_object_list(users)
end
end
end
Which allows for filtering the users the current user is allowed to see right at the dao layer. The UserDao is dependent upon knowing who the current user is, it is a required component, but under the hierarchy it has no access to it, so it would have to be passed in. If it is passed in to every method call, that is a smell =)
Another great example comes in an audit service which hooks into lifecycle events (this is getting aspecty, but so is the concept):
# Stores in Application Context
class AuditService
inject :current_user
inject :current_transaction
inject :current_action
before :current_action, :any_invocation {
log.audit "Invoking user=#{current_user} action=#{current_action}"
}
around :current_transaction, :commit { |action|
log.audit "Committing in user=#{current_user}, " +
"action=#{current_action}, " +
"tx=#{current_transaction}"
begin
result = action.proceed
rescue Exception => e
log.audit "Failed Commit in user=#{current_user}, " +
"action=#{current_action}, " +
"tx=#{current_transaction}"
raise e
end
log.audit "Committed in user=#{current_user}, " +
"action=#{current_action}, " +
"tx=#{current_transaction}"
return result
}
end
Which does aspect-oriented type transaction and action audit logging. State is tracked in the components, bound to the context, but is available throughout the container, assuming there is a valid context in effect (think Spring transaction system, if you've looked into how it is implemented).
This certainly isn't the only way to solve these problems, but hey, it's an interesting one, and not a big step from what IoC containers are doing now.
0 writebacks [/src/java] permanent link
Sat, 05 Mar 2005JamesOfTheDesert pulled a good one on /. today when another Rails article was posted:
> It's a collection of Java Best Practices rewritten in a 'cool' geeky language.
> Nothing new....
Quite true. For example, Java Best Practice #1 is to avoid using long, detailed
XML files for configuration, and instead use the programming languge itself,
which is dynamically loaded and interpreted when needed.
Another Java Best Practice is to let the framework write the tedious boilerplate
code for you. For example, in Struts, you just run
% struts myAppName
and you're halfway done writing your Web application.
Here's one more Java Best Practice: Avoid expensive , complex application server
software, and do rapid development using the Web server that is built into the
standard library. Then deploy to the Web server of choice with no code changes
or quirky vendor-specific API hacks.
Maybe it's time to start browsing /. again when stuff like that is modded (Score:5, Insightful)
0 writebacks [/src/java] permanent link
Fri, 04 Mar 2005
Free 1 Day Open Source Conference in Philly =)
March is crazy conference month around here. My employer (Chariot Solutions) along with Addison Wesley and Computer Aid, Inc., is sponsoring a free Open Source in the Corporate World conference on the 22nd of March.
Coolest thing, from my perspective, is that we have a track put together for managers and executives as well as a great set of sessions for developers. I think that helping non-technical decision makers learn more in order to help them make better decisions is critical.
As it's free, space is limited, so learn more about it, and sign up!
Oh yeah, we've got a kick butt keynote speaker: Eben Moglen.
0 writebacks [/src] permanent link
Thu, 03 Mar 2005Aspect Oriented... Common Lisp! and SQL!
The Lisp one is actually interesting, as to my understanding (limited!) AspectJ was an attempt to port the Meta Object Protocol (MOP) upon which CLOS is based to Java... But my understanding of MOP and CLOS is pretty limited, so is pure hearsay.
0 writebacks [/src/lisp] permanent link
Wed, 02 Mar 2005Thank you Ales Novak !
call dbms_xdb.cfg_update(updateXML(dbms_xdb.cfg_get(),
'/xdbconfig/sysconfig/protocolconfig/httpconfig/http-port/text()',
8099))
0 writebacks [/src/java] permanent link
Mon, 28 Feb 2005I've recently been asked a number of times what blogging software I use, and why I use it. To answer these more fully, I use blosxom with a custom design.
I have two problems with most blogging software. The first is that blogs are static and are usually presented as dynamic. Blosxom can run in two modes, static and dynamic. In dynamic mode it is a cgi application which operates much like any other piece of blogging software. In static mode it compiles the site and publishes it to a chosen directory. I use both modes. The majority of this blog is static html which is updated every 5 minutes (only the changed bits). If you go to the writeback bits, that is cgi (so you don't have to wait 5 minutes to see your comment, or other folks' comments).
The second problem I have with most blogging software is that it is remarkably difficult to publish, edit, and work with stories. Blosxom uses a plain text backing store arranged on the filesystem. You can grep it. Rublog has a potentially better system where it will talk directly to CVS, but I've been fine with svn'ing my local repository and rsync to publish. For things like Java, working with a relational database is usually easier than the filesystem, which says something =) Personally, I much prefer working with files for stuff like this. I want to make a change, it is just a vim away.
Some of the things I like would be considered huge drawbacks to other people. Like most compiled vs. interpreted things, static site compilation is a touch trickier -- I had to be able to set up httpd to cleanly switch between the two (not difficult, but trickier than not having to). The benefit is that the blog should be rock solid and fast (340 times faster than the CGI'd version).
Additionally, you have to know how to, and be able to, set up a cron job. Actually, you could ping the cgi script to do it, but cron is easier =)
0 writebacks [/tech] permanent link
Fri, 25 Feb 2005
Rails for Struts-ters, Part 2: The Views
We looked at the basics of controllers for Ruby on Rails. Now lets take a look at rendering stuff. The default view technology for most Struts apps is JSP, which works reasonably well. The default renderer for Rails is ERB.
An ERB template would be named foo.rhtml and might look something like:
<h1>RSVP</h1>
<p>Just to make sure we've got it right, you are?</p>
<table>
<% for invite in @invitations %>
<tr>
<td>
<b><%= link_to invite.name , :action => 'verify_invitation', :id => invite.id %></b>
</td>
</tr>
<% end %>
</table>
Which nicely highlights a big potential beef -- there are scriptlets there! Argh, woe, agony. Well, maybe. You can form your own opinion, but lets take a look at it. Let's look at the scriptlet used here:
<% for invite in @invitations %>
...
<% end %>
This loops through invites in the instance var @invitations. The instance var is defined in the controller (I am trying to follow DHH's advice here, I would prefer to expose it via a helper, personally). The equivalent jsp would be:
<%@ taglib uri="/tags/struts-logic" prefix="logic" %>
...
<logic:iterate name="invite" property="invitation">
...
</logic:iterate>
Disturbingly similar for a very similar thing. The big difference being that the erb template uses ruby, whereas the jsp defines a domain specific language via tag libraries. The JSP lets you drop into Java, but that is feared-and-not-to-be-spoken-of, mostly because people have a bad habit of putting application logic in JSP's, which was the ASP and PHP model (from which JSP was copied, go figure).
Now, RoR supports the equivalent of tag libraries, however, just to make things more fun, look at the lines inside the loop:
<tr>
<td>
<b><%= link_to invite.name , :action => 'verify_invitation', :id => invite.id %></b>
</td>
</tr>
The equivalent JSP/Struts would be:
<%@ taglib uri="/tags/struts-html" prefix="html" %>
...
<tr>
<td>
<b>
<html:link action="/VerifyInvitation" paramId="id" paramName="invite" paramProperty="id">
$invite.name
</html:link>
</b>
</td>
</tr>
The Struts HTML taglib uses a jsp taglib DSL again to define links within the application, in this case Rails uses a Helper named link_to which is built in to the rails framework (Actionpack specifically). Helpers can be defined in several places. For helpers which are to be globally available, defining them on the application_helper is natural, such as:
# The methods added to this helper will be available to all templates in the application.
module ApplicationHelper
# roles == list of roles required to see text
def secure(text, roles = [])
user = @session['user']
return '' unless user
if roles.all? { |role| user.roles.map {|r| r.name }.include? role }
return text
else
return ''
end
end
end
Methods defined on the ApplicationHelper are exposed as helpers to all views in the application. This example defines a single helper, secure which will return (and hence render) the text passed as the first argument if and only if the logge din user is in all of the roles passed in the array for the second argument, so it would be used like:
<%= secure link_to('Accepted Guests', :controller=>'rsvp', :action=>'accepted'), ['admin'] %>
Which will render a link to an action which lists the guests who have accepted invitations if the logged in user is in the role admin.
In addition to defining helpers ~globally, you can define per-controller helpers in a [ControllerName]Helper module, which will be automatically mixed into the controller it is executing for, so it will have access to that controllers scope. Helper modules can be explicitely mixed into a controller view the helper function, in addition to the implicit helper module. Finally, you can expose methods on the controller itself as helpers via the helper_method and helper_attr functions. Basically, you can define helpers in ways that are convenient for you. You can also declare that you need helpers, using the helper function directly in the template, which is analogous to declaring that you need a tag library in JSP.
That is a basic overview, now for more fun stuff, like form handling. I won't go into explaining Struts ActionForms, you presumably know all about them already. Rails places form parameters into an @params instance var on the controller. It supports structured form parameters, like the EL properties in Struts, but via more-natural-for-ruby hashes, take for example the following form:
<form action="<%= url_for :action => 'register', :controller => 'rsvp' %>" >
<table>
<% @invite.number_of_seats.times do |slot| %>
<tr>
<td>Guest Attending:</td>
<td>
<input type="text"
name="invite_names[<%= slot %>]"
length="30"
<%= "value='#{@invite.split_names[slot]}'" %>/>
</td>
<td>
<input type="radio" name="dinner[<%= slot %>]"
checked="true" value="chicken" /> <b>Chicken</b> or
<input type="radio" name="dinner[<%= slot %>]"
value="seafood" /> <b>Salmon</b>
</td>
</tr>
<% end %>
<tr>
<td> </td>
<td><input type="submit" value="Continue"/>
<td> </td>
</tr>
</table>
</form>
An invitation has a specified number of seats attached to it (ie, if you invite a family of four, it is four, a couple it is two). We loop this number of times:
<% @invite.number_of_seats.times do |slot| %>
...
<% end %>
Assigning the index of the current seat to slot. Now, with this we build up the input names, such as:
<input type="radio" name="dinner[<%= slot %>]"
checked="true" value="chicken" /> <b>Chicken</b> or
<input type="radio" name="dinner[<%= slot %>]"
value="seafood" /> <b>Salmon</b>
where the name of the parameter is dinner[<%= slot %>], so we'll have things like dinner[1] and dinner[2]. On the controller side
def register
names = @params['invite_names']
names.each do |key, name|
if name and name != ''
u = User.new('login' => name.downcase.strip, 'name' => name.strip)
u.attending = true
u.meal_preference = @params['dinner'][key]
u.save
@session['user'] = u unless @session['user']
end
end
invite = Invitation.find(@session['invite_id'])
invite.accepted = true
invite.save
redirect_to :action => 'thank_you' and return
end
we'll pull those out the indexed dinners (indexed the same as the user names ;-)
names.each do |key, name|
...
u.meal_preference = @params['dinner'][key]
...
end
Note that names is a hash, so names.each will include the key and the value. In this case the key is an number, but it is not in fact ordered, it is like a Map. Despite iterating over names (to pull out the other info), we are going back to @params for the dinner hash and looking up values in it. I picked this example as it is somewhat complicated, most often you don't need to do much this fancy.
Now, JSP 2.0 introduced JSP 2.0 Tag Libraries, which are basically global macros. It seems that the Struts mail reader example app doesn't use them, but we'll assume you know about them. They are a nice way of thinking about Rails partials. Partials are basically little included snippets for things that are likely reused, or complicated, etc. Take for example a snippet for rending a table of things in a gift registry:
<% gifts = gift_table %>
<table>
<% for gift in gifts %>
<tr>
<td><%= link_to gift.name, :action => 'show', :id => gift.id %></td>
<% unless gift.being_given? %>
<td>
<b><%= link_to 'Give this Gift', :action => 'give', :id => gift.id %></b>
</td>
<% end %>
</tr>
<% end %>
</table>
which is used here:
<h2>Gifts Not Yet Selected</h2>
<%= render_partial 'gift_table', @gifts.find_all {|g| not g.being_given? }%>
<h2>Gifts Being Given</h2>
<%= render_partial 'gift_table', @gifts.find_all {|g| g.being_given? }%>
The partial takes a single argument named gift_table which is a collection of
gifts to be rendered in a table. There is actually a convenience function for this exact use case (passing a collection in), but I didn't see it when I wrote this, so didn't use it, oops. The render_partial helper in the template passes in the collection to be assigned to the name 'render_partial'. Works nicely.
In JSP 2 tag file format, this might look something like (table.tag, totally untested and unvalidated, and just as pseudo-template ;-)
<%@ taglib uri="/tags/struts-logic" prefix="logic" %>
<%@ attribute name="gifts" required="true" %>
<table>
<logic:iterate name="gift" property="gifts">
<tr>
...
</tr>
</logic:iterate>
</table>
and be called via
<%@ taglib prefix="gifts" tagdir="WEB-INF/tags/gifts/" %>
...
<gifts:table gifts="unselectedGifts" />
<gifts:table gifts="selectedGifts" />
Final thing to look at in views is layouts. The quasi-official tool for this in Struts is Tiles, but I prefer Sitemesh, so will use a sitemesh example. Rails has Layouts, which are the same conceptually as Sitemesh decorators. Here is one
<html>
<head>
<title>Brian and Joy's Wedding</title>
<link href="/stylesheets/scaffold.css" rel="stylesheet" type="text/css" />
</head>
<body>
<%= render_menu %>
<%= @content_for_layout %>
</body>
</html>
The layout gets wrapped around any rendered output, with the output going at the <%= @content_for_layout %> point. The easiest way to use a layout for all views is to just have a layout named application.html, and it will be used implicitely. You can explicitely use a layout by declaring it in the controller, a la
class GiftController < ApplicationController
layout 'scaffold'
before_filter :require_logged_in
which will have it look for scaffold.rhtml to use as a layout. Sitemesh uses an external XML file to configure these, under typical usage, but it is conceptually the same.
RoR 0.10.0 introduced components, which I haven't used yet myself, so cannot comment much on. I suspect they are to be thought of like JSF components. You can investigate these further in the component documentation.
0 writebacks [/src/java] permanent link
Thu, 24 Feb 2005... to have Windows installed anywhere. Just got Starcraft running on my Powerbook =)
0 writebacks [/tech] permanent link
Mon, 21 Feb 2005[rant]
The more I do, and the more I work back towards the world of Tim Bray's 'back-door technology', the more I come to the conclusion that Ted Neward is only half right about O/R Mapping being Java's Vietnam. I think he's only half right because I don't think he took it far enough. The database is a sacred pile of mud That Shall Not Be Touched in the Java world. On TSS every O/R Mapping discussion gets slammed with "the dba (all hail) would never let you do X." Bull shit. Denormalization is only allowed if the DBA holds your hand and signs off. Queries have to be optimizable by the DBA. SQL is the one true god, and the DBA is the path to him (the SQL god is way to insecure to be a female god).
The SQL God spaketh to the DeeBeeAie through a Burning Frog (okay, TOAD, but frogs are special too) and he said "Thou Shalt Profit By Worshipping Me." He explained that "Math Supports Me, So I Am Correct And Provable And That Is Good Because Ye Dirty Programmers Gave Up On Mathematical Provability When Ye Rejected LISP And ML And Haskell And All That Is Good In Maths." Most people repeating the story leave off the second part of that sentence and just say "relational algebra is based on math, so it is good, unlike all those dirty imprecise programming languages that let you do things like pointers."
I think I mentioned before that I got in trouble once for talking about creation myths. I got in trouble because I called the creation stories of a living religion "myths", and the person I was speaking to was a priest. He kindly pointed out that it is only a myth when no one believes it anymore, until then it is Religion or Truth depending on whether you believe it or not. We laughed about this. I digress.
This is religion now. Sorry. I have met some really bright people who Believe in relational algebra, and for the most part they don't particularly like the current implementations commercially available. I find that amusing, and sad. I have met other really bright people who believe in the Database, and hate that people are allowed to do things to its pristine and perfect structure. I've met other smart people who have this totally bizarre idea that the database is a tool to help them solve a problem, nothing more, nothing less. I sort of agree with them.
The Database, compared to the database, is sacred because it is the integration point for everything. The industry was convinced, for better or worse, that Programmers Are Stupid And Do Stupid Things But Databases Are Pure And DBAs Are Perfect about the time that 4GL was popular. Sort of makes sense, in retrospect, and probably was quite true. The Database was the center of the world, and was mysterious, and special, and had special incantations and priests to care for it and feed it. Applications existed to speak to the database, sometimes (blasphemy!) by speaking EssQueueEll directly, but (orthodixically) through the Stored Procedure written by the DeeBeeEh (how do you phonetically spell out "A" anyway?).
Pop quiz: is application integration at the database level the "Right Way" ?
The answer is, of course, "it depends." For a decade and a half it has been either the "right way" or the standard way for a lot of development. This has lead to it being pretty easy to do. Embedded databases are not ENTERPRISE or SCALABLE or SOMETHING-ELSE-THAT-SOUNDS-IMPORTANT. Well, actually... anyway. Externalizing the database isn't a bad thing. In fact it's really good. And taking care of it, and building a correct data model are really good ideas.
But don't worship the bloody thing! Lift your head up from behind the pew in front of you and look at it. Write out some theses and pin them to Oracle's door. Yeah, relational databases do a lot right, but they are tools that are supposed to help you do your job, not be some opaque monstrous thing requiring Holy Intermediaries to intervene on your behalf.
JDBC is crap, sorry, have to say it. It was mostly specced out to expose database features, not make programming easy. Entity Beans are a nice exploratory attempt at making a convenient API, which was a good prototype which got pushed too far. Transparent O/R mapping, the current sacred frog, is another nice shot, I think, but I have yet to see an implementation which isn't painful (including OJB which I find to be the least painful Java one, even if it isn't spelled H-I-B-E-R-N-A-T-E or E-J-A-Y-B-E-R-N-A-T-E) -- (if you need thousands of lines of proprietary XML scripting, or a tool to generate it for you and leave you cursing, to make it work, it is painful). Externalized mapping (iBatis being the current flavor of choice) is a step in the right direction, but is still painful. It continues to worship from below, not celebrate, and has thousands of lines of xml scripting to boot.
The problems all come back to "the database is sacred, and hard, and only the special elite few are allowed to understand it." Give it up. Celebrate the database. It exists for one purpose -- to hold state for you while you reboot, or in case you don't have enough memory to keep it all available yourself. It has lots of gewgaws to make you think it exists to do more (oh its New-cue-ler, erm, I mean Atomic) which, shockingly, ain't that hard to do. Any API which talks to it and holds ANY state and is reliable is also New-Cue-Ler (yep, that includes your Entity Beans, your O/R Mapper, your JDBC abstraction layer, your iBatis, etc). Holy bats, you mean going New-Cue-Ler is not np-complete. You can even get different levels of Nuclear Armament, ones where people can see your state, or where you copy your state and explode if someone changes it before you let go, or... the list goes on. It isn't in the easy category, but sure isn't in the hard category. It is like writing a payroll system, complex, yes, but well understood and not technically difficult, heck, there are whole books written on it.
I am not belittling the importance of maintaining a strong nuclear arsenal. I mean, the only reason we haven't finished conquering the remaining oil producing nations is because they support read-committed isolation. But don't worship your nuclear arsenal, use it. Make a few radioactive parking lots for your SUV driving users. Er, wait, the metaphor is getting totally out of hand here...
A good database is an amazing tool. Stop fighting it. Stop pretending it isn't there. Stop making appeasements to it through specially anointed go-betweens. Use the services it provides to do what they do best -- hold the state which you need to have held. Store it in the way that makes your job easier. Programmer time, despite the best attempts of a lot of sales folk, is still more expensive than database licenses (okay, programmer time of programmers whose work you won't have to pay some other, much much more expensive, programmers to fix, anyway). Go ahead and get your hands dirty -- normalize your schema, denormalize your schema, use dynamically generated schemas (GASP!).
If you are worried about correct behavior, write tests.
If you are worried about integration, expose an integration API via messaging or SOAP.
If you are worried about your job, produce useful software.
That last one is really important. Think about it some. If your job is to spend the IT budget, by all means, worship your database. If you job is to produce useful software, stop fighting and learn to love the bomb. Oops, bizarre metaphor snuck back in.
Maybe copying ODBC and sticking a J in front wasn't the best approach, who knows. I wasn't on the expert group, and cannot whip out the "Right Way" right now; JDBC/ODBC/DBI/etc have all provided lots of good use for years, just like assembly language did (thank you someone on TSS for that reference, not sure who it was or I'd credit you). It is easy to second guess, so I should shut up, but I'd dearly love to have convenient access to the relation constructs in the database from the application language. Give me a handle on a Table, or a ForeignKey =) I'd still even use O/R mapping solutions when they were the best option, I promise!
[/rant]
1 writebacks [/src] permanent link
Tue, 15 Feb 2005Got some feedback on my previous post which is probably best reprinted (now that I've gotten permission) verbatim:
Great article on the comparison of Struts and Rails.
I have a few pointers on how you can make it even better.
1. Rename app/views/layout/scaffold.rb to app/views/layout/application.rb --
then its automatically picked up by all controllers.
2. Using model :user is not necessary unless you don't follow the
User => user.rb model. When you do (and the generators ensure that you do
pretty much all the time), the User model is automatically included when the
class is referenced.
3. These are not necessary: helper_attr :return_to, :user_login. All instance
variables assigned in a controller action is automatically made available to the view.
I'm not sure what the pass_thru is about, but in any case, here's a more idiomatic
Rails controller for your example:
class LoginController < ApplicationController
def index
if @session['user'] = User.authenticate(@params['user_login'])
logger.info "User logged in: #{@session['user']}"
redirect_to_path(@params['return_to'])
else
@session['return_to'] = @params['return_to']
redirect_to :controller => 'rsvp',
:action => 'select_invitation',
:params => { 'name' => @params['user_login'] }
end
end
def pass_thru
@return_to = @params['return_to']
render_action 'login'
end
def logout
reset_session
redirect_to :controller => 'information', :action => 'index'
end
end
--
David Heinemeier Hansson
Nice when the guy who wwrote the framework is poking at your code ;-)
0 writebacks [/src/java] permanent link
This is wrong in so many ways...
I am tempted to bid myself up...
2 writebacks [/stuff] permanent link
Rails for Struts-ters (Part 1)
After looking at the various introductory tutorials for RubyOnRails, a lot of people seem to come away thinking it is a simple CRUD framework -- mostly because of Scaffolding. A common theme seems to be, "well, it looks fast for slapping together a prototype, but when you need control, you it ain't there." I can see why people think that way, after watching the 10-minute video, and the reading the ONLamp tutorial. So here is a stab at a guided tour, using Struts as a point of reference. The 10,000m view of the two is very similar, so this should play out nicely. It is important to note that this is an imperfect comparison in one big regard -- it only really looks at one part of Rails, ActionPack. ActiveRecord, ActionMailer, and the upcoming SOAP/XML-RPC stuff map more along the lines of OJB (or Hibernate, or Cayenne, or JDO, etc), Spring's JavaMail hooks, and Axis respectively.
On to the good stuff.
In both cases the core design is a Request -> Filters -> Action -> Filters -> View pipeline. In Struts you get something that looks like:
/*
* Copyright 2000-2004 Apache Software Foundation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.struts.webapp.example;
/* imports omitted */
/**
* Validate a user logon.
*/
public final class LogonAction extends BaseAction {
static String USERNAME = "username";
static String PASSWORD = "password";
User getUser(UserDatabase database, String username,
String password, ActionMessages errors)
throws ExpiredPasswordException {
User user = null;
if (database == null){
errors.add(
ActionMessages.GLOBAL_MESSAGE,
new ActionMessage("error.database.missing"));
}
else {
user = database.findUser(username);
if ((user != null) && !user.getPassword().equals(password)) {
user = null;
}
if (user == null) {
errors.add(
ActionMessages.GLOBAL_MESSAGE,
new ActionMessage("error.password.mismatch"));
}
}
return user;
}
void SaveUser(HttpServletRequest request, User user) {
HttpSession session = request.getSession();
session.setAttribute(Constants.USER_KEY, user);
if (log.isDebugEnabled()) {
log.debug(
"LogonAction: User '"
+ user.getUsername()
+ "' logged on in session "
+ session.getId());
}
}
public ActionForward execute(
ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
// Local variables
UserDatabase database = getUserDatabase(request);
String username = (String) PropertyUtils.getSimpleProperty(form,
USERNAME);
String password = (String) PropertyUtils.getSimpleProperty(form,
PASSWORD);
ActionMessages errors = new ActionMessages();
// Retrieve user
User user = getUser(database,username,password,errors);
// Save (or clear) user object
SaveUser(request,user);
// Report back any errors, and exit if any
if (!errors.isEmpty()) {
this.saveErrors(request, errors);
return (mapping.getInputForward());
}
// Otherwise, return "success"
return (findSuccess(mapping));
}
}
(note that I am taking all Struts sample code from the struts-mailreader.war example app bundled with Struts).
With rails you get something that looks like:
class LoginController < ApplicationController
layout 'scaffold'
model :user
helper_attr :return_to, :user_login
def index
redirect_to :action => 'login'
end
def pass_thru
@return_to = @params['return_to']
render_action 'login'
end
def login
@user_login = @params['user_login']
@return_to = @params['return_to']
valid_user = User.authenticate(@user_login)
if (valid_user)
logger.info("user logged in: #{valid_user}")
@session['user'] = valid
redirect_to_path @return_to
else
@session['return_to'] = @return_to
redirect_to :controller => 'rsvp',
:action => 'select_invitation',
:params => { 'name' => @params['user_login'] }
end
end
def logout
reset_session
redirect_to :controller => 'information', :action => 'index'
end
end
Both of these have, roughly, something to do with logging in. The rails controller is for an implementation of pass-through authentication very much like the Servlet spec's authentication system. The Stuts one for a classic link-to-the-login-page system. They work for our purpose. Interestingly, the Rails one doesn't use passwords (or even a stored login name, it makes sense when you see the app, don't worry).
Now, presuming you know how to make sense of the Struts one, lets look at the Ruby one. It does a few things differently. First off, all Rails controllers are by default much like the DispatchAction in Struts. Each method defined on the controller exposes an action to the application, so the above LoginController exposes four actions: index, pass_thru, login, and logout.
Form parameters in Struts are passed in via the ActionForm, in Rails you get a Hash (a Map) of values. Much like nested properties in Struts, you can have nested thingamabobs in Rails: @params['users']['bob']['name'] for example -- we'll look at that in more detail later.
Struts uses the return value to indicate a view, rails makes it a call:
render_action 'login'
And defaults to a view named the same as the action invoked (this is important to note as most actions just render their default view, this particular example is weird in that way).
Struts will map the possible responses with named forwards typically, some local to the action, some global. The same concept exists in Rails, but instead of using xml to map these, it uses the file system as a nice indexing system:
brianm@kite:~/Sites/wedding/app$ tree views/
views/
|-- gift
| |-- _gift_table.rhtml
| |-- edit.rhtml
| |-- list.rhtml
| |-- new.rhtml
| `-- show.rhtml
|-- information
| |-- gardens.rhtml
| |-- index.rhtml
| |-- museum.rhtml
| `-- reception.rhtml
|-- layouts
| `-- scaffold.rhtml
|-- login
| |-- login.rhtml
| |-- logout.rhtml
| `-- register.rhtml
`-- rsvp
|-- index.rhtml
|-- register.rhtml
|-- select_invitation.rhtml
|-- thank_you.rhtml
|-- unlisted.rhtml
`-- verify_invitation.rhtml
5 directories, 19 files
brianm@kite:~/Sites/wedding/app$
There are several ways to specify a view to use. The default looks for the [controller]/[action] naming convention. You can also use a named one render "my_fancy_view" if you like, though this is pretty uncommon, I think. It would just look for a my_fancy_view.rhtml view.
Information which would be in the struts-config.xml about redirects, etc, is placed into the controller here, for example the complicated view selection:
redirect_to :controller => 'rsvp',
:action => 'select_invitation',
:params => { 'name' => @params['user_login'] }
sends a redirect to a different action on a different controller (in this case the login failed with no user matching using a fairly sophisticated name to user mapping algorithm (ruby-lucene would be better, alas)) so the best guess is that it is an as-yet un-rsvp'd wedding guest, so it sends em over to rsvp, with a query tagged on to find invitations for the attempted user name.
I can see you turning queazy. It's okay. I am a little uncomfortable redirecting to a different controller, complete with params as well. Redirecting to the same controller is a comfortable level of familiarity, but hey, I took the code as i wrote it, for better or worse =) It nicely illustrates that actions are much more responsible for choosing views in Rails than in Struts
Now that I made you queazy, and apologized, go look for where you have done the same thing in XML for Struts. You should feel even queazier about that, imho. [soapbox]XML is not a scripting language[/soapbox].
The only thing left to look at in Part 1 is the header-y type stuff:
layout 'scaffold'
model :user
helper_attr :return_to, :user_password, :user_login
defined on the controller. These are all slightly different.
The model :user is a convenience declaration to say "make sure everything I need to work with users has been required". Fancy import (fancy as it does nice things like always reloads in devel mode, doesn't in production mode, etc).
The layout 'scaffold' is analogous to using Sitemesh, and we'll look at it in more detail in a later entry, but for now, think of it as declaring a Sitemesh decorator (it is, really).
Finally we have, helper_attr :return_to, :user_login. These are helpers, which we will also look at in much mroe detail later. This specific case exposes two properties to the view, return_to and user_login. It is like setting them as attributes on the HttpServletRequest so that you'll have them in your JSP. Actually, it is just like that -- you expose them to the view template. The values are taken from the instance variables @return_to and @user_login respectively, which we set up in the actions.
Okay, start of the whirlwind comparison tour. More to come! Bedtime now =)
1 writebacks [/src/java] permanent link
Fri, 11 Feb 2005I'm happy to share CodeMonkey.
CodeMonkey is a programmatic code generation tool. It is not a template based code generator like XDoclet or its ilk, it is entirely programmatic, for instance:
public void testSample() throws Exception
{
Klass wombat = new Klass();
wombat.setName("Wombat");
wombat.setPackage("org.skife.example");
Method belch = new Method();
belch.setFinal(true);
belch.setName("belch");
belch.addParameter(new Parameter("int", "volume"));
belch.setBody("System.out.print(\"BURP at level \" + volume);");
wombat.addMethod(belch);
BeanTool.addProperty(wombat, String.class, "name");
BeanTool.addProperty(wombat, "int", "age");
wombat.addInterface(Serializable.class);
Generator generator = new Generator();
String source = generator.generate(wombat);
System.out.println(source);
}
Will generate the output:
package org.skife.example;
public class Wombat implements java.io.Serializable
{
private java.lang.String name0;
private int age1;
public void belch(int volume)
{
System.out.print("BURP at level " + volume);
}
public final void setName(java.lang.String name)
{
name0 = name;
}
public java.lang.String getName()
{
return name0;
}
public void setAge(int age)
{
age1 = age;
}
public int getAge()
{
return age1;
}
}
The library just has low level constructs right now (java language features), but more is sure to come, as I built it to solve other problems ;-)
CodeMonkey is *not* a replacement for XDoclet, Middlegen, etc. It *is* a useful tool for building semi-dynamic code (ie, from JDBC metadata or whatnot) at compile time.
Have fun!
0 writebacks [/src/java] permanent link
Mon, 07 Feb 2005Cleaned up my bash commpletion for ssh some, figured I'd put it up so can people can show me what they have that's better ;-)
SSH_COMPLETE=( $(cat ~/.ssh/known_hosts | \
cut -f 1 -d ' ' | \
sed -e s/,.*//g | \
uniq | \
egrep -v [0123456789]) )
complete -o default -W "${SSH_COMPLETE[*]}" ssh
You can drop the final egrep -v [0123456789] if you regularly ssh to ip addresses =)
3 writebacks [/tech] permanent link
Jamis Buck has been going crazy lately. The pure-ruby ssh client library is pretty slick. All that said, the docs he's produced are the slickest part. Cannot understate the importance of documentation =)
Of course, I am also waiting for this announcement. Ah, the pain of using incrementing ids from sequences ;-)
0 writebacks [/src/ruby] permanent link
Thu, 03 Feb 2005Rusko (don't have a better name for him) got me thinking the other night by doing the dastardly deed of pointing nevow out and discussing why apache (web server) sucked (his words, not mine (for throughput-oriented, highly static, sites)).
So, here is a stab at a design to maximize network throughput. It makes use of some things that don't exist in Java (yet, hopefully) so please excuse the rubyish pseudocode.
We start with a simple looping process:
class Looper
def initialize
@loop = Loop.new
@loop << HttpAcceptor.new(@loop, 80)
end
def start
@finished = false
callcc do |escape|
@loop.cycle(:http) do |bucket|
bucket.continue(callcc { |c| return c }) if bucket.ready?
@loop.remove(bucket) if bucket.finished?
escape.call if @finished
end
end
end
def stop
@finished = true
end
end
A couple pieces of magic there. Loop is the first one. This is a cyclical linked list which supports internal iteration via Loop#cycle where it is passed a cycle key, which identifies which things in the loop we care about (there may be things in the loop we don't know how to handle, this one handles http stuff, another might handle database stuff, but they can share a loop). Importantly, iteration is threadsafe (lets pretend that Ruby supports native threads, why this is important later) and while an element is "held" by an iterator, it is skipped over as if not there by any others.
The second piece of magic is the HttpAcceptor. This just handles accepting tcp connections, and implements the (server side) http protocol. It is a protocol abstraction layer which uses asynchronous IO (NIO for the Java folks). It also implements the Bucket protocol, which we haven't met yet. Note that it is passed the @loop variable. When it receives a new connection it instantiates a Request and adds it to the loop. Where in the loop doesn't actually matter, which is nice.
Now, the Request is interesting:
class Request
def initialize(loop, content_generator)
@loop = loop
@content = content_generator
end
def continue(go_back)
@go_back = go_back
if @pickup
@pickup.call
else
content.start(self)
end
end
def return_when(key)
@loop << Bucket.new(key) { yield }
callcc do |c|
@pickup = c
@go_back.call
end
end
def finished?
content.finished?
end
def ready?
@content.ready?
end
end
The Request is created and given a content_generator which is much like a Java HttpServletRequest. The Request in this case just handles passing control around, and the content_generator does the interesting stuff (ie, is used by people writing apps). We'll see an example of one shortly =)
The Bucket is just a bucket implementation which is finished when the block it is passed in its initializer finishes. It responds to cycles asking for its key.
Now, the content generator may be really simple:
class SimpleContent
def initialize(out)
@out = out
end
def start(request)
@out.puts "Hello World"
end
def finished?
true
end
end
But that is boring, lets look at something that needs to do something where it yields control to a slow process...
class InterestingContent
def initialize(out)
@out = out
end
def start(request)
@out.puts "Bouncer likes "
request.return_when(:database) { @puppy = Puppies.find_by_name 'Bouncer' }
@out.puts(@puppy.favorite_toy)
@finished = true
end
def finished?
@finished # nil == false
end
end
Now, this is much more interesting because it uses the Request#return_when which queues out the (io bound) database call. It specifies it is a :database operation, and does its stuff.
Now, lets follow a single thread of execution from socket connection through to response completion.
- The looper asks the http acceptor if it is ready, which it is. It then captures a continuation where it is, and passes that continuation into the acceptor.
-
The acceptor sees if it has enough information in its io buffer to build a Request, it does! It matches the url to the
InterestingContentgenerator via some means, creates an io buffer, and instantiates generator, uses that to create aRequest, drops the request in the loop, and invokes the continuation it was passed. - We're back where the continuation was created, where the next thing is to ask the current bucket if it is finished. The acceptor is never finished, so it says no, and the cycle loops to the next bucket, which, low and behold is the request that was just created! Hey, cool.
- The looper asks the request if it is ready (it is) and so captures a continuation, and passes it into the request (with an interesting generator). Now the fun begins.
-
The request stores the
go_backcontinuation and looks to see if it has an@pickupinstance var. It doesn't, so it starts the content generator, passing in itself. -
The content generator spews some output into the buffer and realizes it needs to ask for something slow, a database lookup! Oh no! Doing this inline here would block THE WHOLE SERVER on io to the database, so instead it asks the request to schedule a database operation via the
return_when(:database) ...call. Now this is interesting... -
The request kindly plunks the requested operation into loop, and then captures a continuation right before returning back to the content generator. Instead of returning, though, it invokes the
@go_backcontinuation, which goes back to the looper... - The looper picks up and asks the request if its done, it isn't, and it looks for the next bucket, which is the acceptor, which has nothing interesting so isn't ready, and comes back to the request, which is waiting on the database stuff... Now, smoke and mirrors for a second, pretend the database stuff somehow completed. We'll look at how that happened in a moment, don't worry, accept that it did, please.
-
The request is ready, so we continue it. Now the request sees it has an
@pickupso it invokes it. -
And we're back in the call to
return_towhich promptly returns to the interesting content generator, which now has the puppy it was looking for, so it spews some more stuff to the output buffer and says its finished. - The request comes back up, the looper sees things the request is finished, so removes the bucket (okay, I forgot to flush the io buffer to the output socket, I'll leave that pseudo-code as an exercise to the reader ;-)
- The looper continues in a busy-wait until another socket comes in. Probably this could be handled via registering an interrupt, but that too is an exercise for the reader and is irrelevent for the main point =)
Now, this is all a single-process operation. There is a co-routine set up between the looper and the request, trading control back and forth via invoking continuations whenever an operation will not be able to execute immediately (needs network io, database io, etc). This maximizes processing time by allowing the cpu to be churning whenever there will be (an expected) io wait. The real impl will be significantly trickier as it needs to do the selecting on io streams, but hey, this is pseudo code for the concepts.
No threads, one process, way higher throughput under heavy load. Sort of scary.
Now, to go back to the loop being thread safe despite there being no threads, and Ruby supporting native threads -- on a multi-cpu machine you start one looper per cpu on the same loop instance =)
Now, what about the database? Well, two things -- you could have a dedicated database process, but this seems rather inefficient unless the database is going all the time. Instead, have a similar setup for the database, and add it to the loop as a Bucket! You can loop through the loop from a bucket in the loop, same type of coroutine as the looper/request, but is now HttpLooper/DatabaseLooper, where the http looper and the database looper are both in the loop, and trade control back and forth.
Now, we can get more fun by not making the loop an actual loop, but a priority queue instead!
4 writebacks [/src] permanent link
Tue, 01 Feb 2005Without breaking out a compiler, or BeanShell ;-), what is the output from the following:
System.out.println("**" + foo != null ? foo : "NULL" + "**");
If foo is the String "wombats!"? What if foo is null?
;-)
7 writebacks [/src/java] permanent link
Mon, 31 Jan 2005Just pushed jDBI 1.2.3. Much thanks to Patrick and Robert for prodding me make a couple big changes, and for prodding me to not make those changes until I found the right way, respectively (for 1.2.2 (transparently handling different transactional contexts) and 1.2.3).
The biggest change is making externalized SQL pluggable. It was something that had been itching for a while (previously it could only pulled named statements from the classpath, though pretty smartly), and Patrick's need for sticking the SQL in the database prodded me to finally support that explicitely. He's not using it, I don't think, but you'd better bet I will before too long =) Maybe stick them in a JNDI or an LDAP instead, or whatever. It's all good.
Speaking of the classpath approach, what I did on the last new thing I used jdbi for was to take advantage of Java's nice resource loading and bundle all the sql into its own jar, under an sql/ directory, so you'd have:
sql/
find-foo-by-id.sql
find-foo-by-name.sql
...
Map foo = handle.first("sql/find-foo-by-id", Args.with("id", new Long(fooId)));
Map same_foo = handle.first("sql/find-foo-by-name", foo); // gets "name" from map
The hack here is that the named statement is fetched correctly, and if you unzip the sql.jar to tweak the sql, it's in its own dir, not the working dir. This is minor, but I have things that untar (zip|jar) into the working directory =)
Anyway, the release is up on Codehaus. Have fun!
2 writebacks [/src/java/jdbi] permanent link
Fri, 28 Jan 2005
The Sysadmin School of Programming
In firing off an email on FARP (FreeBSD, Apache, Ruby, and PostgreSQL) programming to ruby-lang today I edited out a flip comment which has hung around in my head for a bit:
FARP grew more out of the sysadmin tradition of development (we have a
good ls, lets use it) rather than software engineering (we need to
re-implement ls because we require
<?xml version="1.0" encoding="UTF-8"?>
<system:command xmlns:system="http://www.example.com/xml/ns/system"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.com/xml/ns/system
http://www.example.com/xml/ns/system"
system:name="ls">
<system:option>LONG_FORM</system:option>
<system:option>
<ls:location xmlns:ls="http://www.example.com/xml/ns/system/ls"
xsi:schemaLocation="http://www.example.com/xml/ns/system/ls
http://www.example.com/xml/ns/system/ls">
CURRENT_DIRECTORY
</ls:location>
</system:option>
</system:command>
instead of "ls -l") tradition of development ;-)
I come from the software engineering school, but got waylaid into the sysadmin school a couple times during critical points in my programmery edumacation. The sysadmin school tends to say "we're running on Apache 1.3 because it is solid and doesn't use threading, which is just multiprocessing done in such a way as to make bugs, anyway." It can be mind-numbingly frustrating at times (try finding a dedicated hosting service which runs current FreeBSD stable (5.3) as FreeBSD folks tend to be sysadmin school, and 5.X is way too new to be stable, despite what the careful and conservative-as-heck FreeBSD release engineering team says, we'll stick with 4.9, thank you, or maybe go to 4.11 if you really need it for some reason, which you don't).
The sysadmin school folks are right, of course. It goes back to the novelty junky stuff.
;-)
4 writebacks [/src] permanent link
Tue, 25 Jan 2005Does Ruby auto-complete =) Rock on!
Add the following to your .vimrc:
function InsertTabWrapper()
let col = col('.') - 1
if !col || getline('.')[col - 1] !~ '\k'
return "\<tab>"
else
return "\<c-p>"
endif
endfunction
Then use ctrl-p to autocomplete
Many thanks to bougeyman in #rubyonrails
1 writebacks [/src] permanent link
Fri, 21 Jan 2005It is scary (FEAR FEAR) to see opinions formed, and backed with vitriol, by fear that something different than what they are doing works better. Something you don't know that approaches the same problems as something you do know does not make the first thing bad. It does not justify lashing out at it saying "it is just [foo] and sucks so bad compared to [bar] and can never [scale|perform|manage|eat] enough to be used for [serious|difficult|real] things." Possibly this is true, but reacting that way out of fear certainly does not make it so.
The pattern emerges all over. It scares me. It also encourages me because it means that when a better way comes along most people won't realize it, and even if they do they will let themselves be riddled with fear of it changing things, so that those who are willing to try something before hating (fearing) it will have a big leg up. Wait, this happens all the time too!
Seriously, next time you are tempted to glance over something and immediately say "ah, it is [pigeon hole] and therefore crap." Maybe put aside your fear that someone, somewhere, has found a better way to do something and give it a real whirl.
Luckily, most people will read this, presume they are in the category of person who honestly evaluates things before hating them, and then go on their merry close-minded way =) I say luckily because that leaves more goodness for everyone who does stop and work through things.
Putting your head in the sand and ignoring new things, or attempting to will them out of existance, or convince everyone around you that they are bad so the whole flock has its head in the sand with you, because something conflicts with your status quo is certainly a time-tested way of dealing with change -- for a while.
Finding the opposites of abstract things can be a fun game. I think the opposite of fear may be curiosity.
2 writebacks [/src] permanent link
Thu, 20 Jan 2005
ROFL (literally if you count spinning around in my chair laughing...)
From Tim Lesher, Choose Python has a fantastic quote:
... Choose an almost-fanatical devotion to the BDFL, unless he comes up with something like optional static typing, in which case choose to whine about it in your blog until he stops. ...
=)
2 writebacks [/src/python] permanent link
Wed, 19 Jan 2005Happy morning =)
brianm@kite:~/.opt/postgres-8.0$ ./bin/psql test
Welcome to psql 8.0.0, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
test=#
Now for some XA support...
2 writebacks [/tech] permanent link
I have been lax in announcing jDBI related stuff -- time to make up for that =) First, jDBI made its 14th and 15th (1.1.2 and 1.2.1 -- seperate branches). Technically 1.2 maintains bytecode compatibility with 1.1 (you can drop the jar in and go) but there is a huge seven character difference. DBIException now extends RuntimeException per a bunch of strong arguments by Patrick Burleson. Seven characters, world of difference. Guess I have taken the dive into optional exception checking. Water still feels chilly.
Aside from API changes, hosting has moved to the Haus. The subversion repo isn't there yet, but the rest is. No pretty confluenze site (yet?). We also have mailing lists! I should probably post them on the site sometime soon... In the mean time, its not hard to figure out my email address, or the lists if you look at how Bob lays out projects ;-)
As the last release I announced was 1.0.X series, some other big things in there include really nice Spring integration (factory bean which makes a couple minor changes to play as expected and hooks into the platform transaction system, and DBIUtils to provide transactionally bound handles/access/etc)
Meeting a few feature requests there is a really nice batch and prepared batch system with usages looking something like:
public void testBatchOfTwo() throws Exception
{
handle.batch()
.add("insert into something (id, name) values (1, 'one')")
.add("insert into something (id, name) values (2, 'two')")
.execute();
final Collection results = handle.query("select id, name from something order by id");
assertEquals(2, results.size());
}
public void testPreparedBatch() throws Exception
{
handle.prepareBatch("insert into something (id, name) values (:id, :name)")
.add(new Something(1, "one"))
.add(new Something(2, "two"))
.add(new Something(3, "three"))
.add(new Something(4, "four"))
.execute();
assertEquals(4, handle.query("select * from something").size());
}
public void testPreparedBatch2() throws Exception
{
final Something[] things = new Something[]
{
new Something(1, "one"),
new Something(2, "two"),
new Something(3, "three"),
new Something(4, "four")
};
handle.prepareBatch("insert into something (id, name) values (:id, :name)")
.addAll(things)
.execute();
assertEquals(4, handle.query("select * from something").size());
}
That one is my favorite. I rarely used batched sql when working with jdbc directly as, well, it is bloody inconvenient. Do it all the time now =)
A particularly fun piece is not actually released yet as I am not satisfied that I have caught all the edge cases -- Henri Yandell asked for in-clause expansion. That is, bind a collection or array to a single formal param for an sql in clause, a la, select id, name from something where id in ?, which could have a List<Long> bound and would expand as required to behave correctly (ideally as a prepared statement still). As I said, I have code which does it, but it is buried in subversion and not exposed yet as I had wanted to avoid fulling parsing and transforming the sql. Still, that is powerful stuff, so it'll probably be the next significant feature.
Anyway, enjoy it and have fun! Remember, SQL isn't teh ev1l, JDBC is just inconvenient! Let the code do the work =)
0 writebacks [/src/java/jdbi] permanent link
Tue, 18 Jan 2005We all know our PickAxe book:

But are there a bunch of young semi-English-speaking programmers in Japan who now think "pickaxe" means "bunny"?

Interesting...
Mighty ferocious looking nubby!
2 writebacks [/src/ruby] permanent link
Sun, 16 Jan 2005
Re: Groovy Closures and Related Syntax Issues
Mike Spille has been putting his money where his mouth is in regards to Groovy, and it is definately a good thing to get good feedback =)
I want to expand on something which he touches on, but then munges up with another concept -- closures and anonymous functions. Closures are *lexical* in nature. A closure is a closure over a lexical scope. Lexical scope is the text of the program, not the stack it is evaluating in. Mike's explanation describes lexical scope more along the lines of dynamic scope (which is a whole other beast, only commonly encountered in elisp) intersecting with lexical scope. Mike explains the concept well, but then forgoes picking on Groovy for ramming the the two together when talking about them, and accepts them as is. Maybe Mike is nicer than me in that regard, I'm am going to pick a nit in this regard and seperate them.
You can achieve (limited) lexical closures in in Java using anonymous inner classes. Swing's event model is predicated upon them, even. Take the following:
final Object flag = new Object();
final int[] jobs_queued = { 0 };
for (int i = 0; i < job_count; ++i) {
Job job = new Job(new Runnable() {
publc void run() {
doSomethingLongAndAnnoying();
jobs_queued[0]--;
synchronized (flag) {
flag.notify();
}
}
});
for (;;) {
try {
executor.execute(job);
jobs_queued[0]++;
break;
} catch (InterruptedException e) {}
}
}
blockUntilCompleted(jobs_queued, flag);
The above code creates a Job and passes it to some asynchronous executor (actually using Doug Lea's util.concurrent package, with its InterruptedExceptions =) Now, this job takes as an argument an instance of Runnable, in this case implemented as an anonymous inner class. The scope of the run method in this Runnable encloses the scope in which it is defined. It accesses and even modifies variables (final ones, anyway) in the local scope of the method body in which it is defined (jobs_queued).
Now, note that this runnable is going to be executed in a seperate thread, in a different stack, and will still modify items in this scope. The scope of the run method encloses the scope in which it was defined.
Where closures get really interesting is in defining anonymous functions -- something that Lisp, Python, Ruby, Groovy, C#, etc all make really easy, and Java doesn't allow (anonymous classes with a single method yes, just the function, no). This is where you get into functional programming styles, which Java allows for, but not in a syntactically pleasent way (like doing objects C -- there are multiple ways of doing it, but none are really as nice as languages with a syntax designed to make it nice (Java, for instance)).
A lot of groovy's anonymous function (called closures in groovy space, something which needs to be changed imho) syntactic sugar stems from emulating the awesome power of Ruby's blocks while not having the block concept. Mike rails at some of the language oddities introduced by having all blocks be anonymous functions, rather than just be blocks. Ruby's blocks are not anonymous functions when created:
irb(main):001:0> foo = { puts "hello world" }
SyntaxError: compile error
(irb):1: syntax error
foo = { puts "hello world" }
^
(irb):1: syntax error
from (irb):1
irb(main):002:0>
But they can be used to create anonymous functions very easily:
irb(main):004:0> foo = proc { puts "hello world" }
=> #
irb(main):005:0> foo.call
hello world
=> nil
irb(main):006:0>
Blocks are their own thing in Ruby, and are used all over the place. The most visible is as a special argument to a function different from other arguments:
irb(main):011:0> 5.times { |i| puts i }
0
1
2
3
4
=> 5
irb(main):012:0>
Interestingly, the block, { |i| puts i } is not an argument to the times call. It is a block passed in, as can be seen most easily by looking at the error message if you skip it:
irb(main):012:0> 5.times
LocalJumpError: no block given
from (irb):12:in `times'
from (irb):12
from :0
irb(main):013:0>
Ruby allows the passing of a block to any function, the function may or may not *do* anything with it. It is a special argument which can be passed. This may seem like a bizarre special case, but it is actually wonderful when used in practice (it probably drives python people nuts, though, as it is too pragmatic ;-)
Now, Ruby and Groovy share a lot of similarities, and having the concept of blocks is one of them, though they implement it quite differently, and that makes for some semantic differences as well. Groovy does not have any kind of implied block parameter to functions, you must explicitely declare passed blocks as a param (though you don't need the &foo "this is a function" stuff). A bare block is a valid expression which returns an anonymous function.
This may be nice, and is certainly a but easier to digest as there is a definate stumble when people start writing functions in Ruby which accept blocks (wait, I yield to invoke it? huh?). It feels natural when you get it, but maybe that is because you just accept it, and passing a block as a formal param seems reasonable (though it is tricky as for syntactic nicety you want it to be last, but if you have a variable number of args, deciding if it is the final arg, or a block is... ick -- I do like Matz's solution, but it certainly is not the only way).
Groovy is strongly object oriented, but it is also strongly functional. It really encourages you to pass functions around -- and makes it easy to munge scopes. Building a lot of the core language syntax around support for this is a design decision, and a decision I have actively supported in the past, and will continue to in the future. It is good design, even if it is different from Java. You certainly don't have to use it, but it allows for much more expressive (expressive != terse) programs, and that is very good.
2 writebacks [/src/groovy] permanent link
Wed, 12 Jan 2005
You know you've been writing too much Java when...
Your head explodes at seeing a method signature like void *do_stuff(void[]) =)
1 writebacks [/src/c] permanent link
Mon, 10 Jan 2005Go read my blog here...
Generated via translating my blog from German to English via Google translate. Yes, the English text translated from German to English ;-)
0 writebacks [/stuff] permanent link
I am, I am happy to admit, a novelty junky. I am comfortable using new tools and have been quite comfortable deploying customer-facing applications with unproven (to whom are these things ever "proven" anyway? As a profession we gave up on mathematically provable software before I even started programming) tools or libraries. As an ex-coworker put it once, "if the technology isn't actually ready yet, you tend to go help build it." I land in the early-adopter camp of the technology curve most of the time, and it treats me well. All of that said, Allen Holub's recent article made me cringe, really hard, because, I believe, it conflates two different problems in an effort to prove a (quite valid) point. The early-adopter segment, which Allen is speaking from (and he knows a lot more than I do), and in which I lump myself, does not represent the profession, not by a long shot.
Quotes like, "Hibernate is the standard persistence technology right now," are crazy. Hibernate is the standard persistence technology for the tragically hip. Heck, it may be passe for the tragically hip already -- I think JDBC is coming back into vogue. Retro, you know?
The reigning gems of hipness which have passed from chic to fashionable seem to be Hibernate, Spring, Webwork, and Jetty. All are wonderful technologies, none of which can be remotely called "standard technologies," however. The interesting bit here is that they have been designed for people who are relatively smart and competent developers. Spring in particular is a fine tool in the hands of a skilled programmer, and an out of control band saw in the hands of the incompetent.
Servlets are a standard technology. Struts is a standard technology. EJB is a standard technology. JSP is a standard technology. JDBC is a standard technology. The Apache Web Server is a standard technology. Heck, even Linux is a standard technology now, despite its politics. A standard technology is ubiquitous, and is rarely fashionable *.
This throw-away stab at EJB, "I personally believe that EJB has been responsible for the failure of more companies than almost any other single technology," is potentially the scariest part, though, as it melds so nicely into the fashionable view that most people won't even pause to think about it. He is right, because he throws in, "than almost any other single technology," but the implications of the statement are completely off. Companies don't fail because of EJB, or any other technology, they fail because of mismanagement or natural disaster. Mismanagement may be, "we are going to use EJB," coming from someone (management, armchair architect, a junior programmer with a Wombat.com Distinguished Engineer title) and the development team not knowing enough to say "that is inappropriate for this application, here is why...", which is really a human resources policy (failure) based on hiring incompetent people who are less expensive.
The interesting bit here, in my opinion, is that a big part of what the EJB movement has been about is taking less skilled developers and helping them create reasonably complex and reliable software. That is great marketing for app server vendors: "spend lots on this product which makes cheap programmers as productive as expensive programmers and you won't be dependent on those expensive and finicky programmers anymore." Corporations are very risk-averse and putting your eggs in one basket (a top notch programmer) is risky. One really good developer is much more expensive, and much harder to replace, than a college grad with a "this solves 80% of the problem" application server (note the magic 80%). J2EE is 4GL for the backend.
I take Allen's point to be that EJB is a standard created from the ether, and supported by a consortium of companies interested in prolonging their various business models more than raising the state of the art. The implication is that the rest of the JCP is the same thing, with James Gosling cast as Darth Vader (he was a great hero, now he's evil, but we all know he'll turn good again).
The JCP is a political battefield for J2EE vendors as well as a standards body. Some gems treat it as a standards body, others as a tool for creating barriers to entry. I suspect that is simply an unpleasent reality that is tough to change. Most of us want to make money, and some ways of doing so (some very profitable ways) do not involve solving problems, but rather prolonging them. I do think the JCP is relevant, but not all JSR's are (JSR220 is quite relevant, despite my jabs). The resistance that has been put up any type of standardization for AOP is a great example of good things in it. I suspect in another five years that Jonas Boner will be a spec lead for an AOP JSR, but as anyone seriously involved with AOP will tell you, it ain't mature enough to standardize, yet.
Allen seems to feel that once something is mature, it is the standard, and making a formal standard is pointless. Every RDBMS vendor has a slight variation on SQL, ever C compiler its extensions. You can say "this is where it varies" though. If you know GNU C, and need to write Microsoft C, finding the differences is easy (they're documented). Having the standard lets you do that. The JCP has some nasty licensing terms associated with its standards, which makes this tough (you cannot partially implement a JCP standard and still be allowed to use its name, except in JDBC, for instance). The JCP is wonderfully inclusive though (not as much as the IETF) and is getting better about back-room specs. Standards are useful, and making them is painful. The JCP pain is certainly less than the twitches I see from people who were involved with SQL though ;-)
*) I think the (standard technology) Apache Web Server is becoming fashionable in Java circles, mostly because people are (re) discovering that you can use Ruby or Python with it to get Java-level or better performance because, imagine this, all the infrastructure heavy lifting is in C optimized for performance (httpd, postgresql, fastcgi, memcached), and all the application logic is in a nice high level scripting language optimized for expressiveness, go figure.
4 writebacks [/src] permanent link
Sun, 09 Jan 2005
Futures 3: Transparent Futures in Java
After looking at futures in Java, then transparent ones in Ruby, adding transparent futures in Java turned out to be pretty simple as well. Just added this method to the two evaluators (duplication bad, yes, but I don't feel like making a new factory dependent on an Evaluator, so =P):
public Object promise(Class k, Expression e) {
final Future f = this.promise(e);
return Proxy.newProxyInstance(k.getClassLoader(), new Class[] {k}, new InvocationHandler()
{
public Object invoke(Object o, Method method, Object[] objects) throws Throwable {
return method.invoke(f.getResult(), objects);
}
});
}
Used like:
public void testSomething() throws Exception {
final boolean called[] = { false };
final Map map = (Map) lazy.promise(Map.class, new Expression() {
public Object evaluate() throws Exception {
called[0] = true;
final Map map = new HashMap();
map.put("a", "A");
return map;
}
});
assertEquals("A", map.get("a"));
assertTrue(called[0]);
}
This only works by interfaces, but using AWProxy instead would be trivial =) If Apple would let me have a 1.5 JDK I might use generics instead, but alas...
Now, async and lazy futures are fun and all, but I think it is time to stop looking at how to implement and look at how to use.
1 writebacks [/src/java] permanent link
Sat, 08 Jan 2005Okay, we looked at Java, which has futures built-in in 1.5, though rather non-transparent futures, compared to something like the referenced Alice. Took some time last night, and today during some breaks in some training (ah, companies which do in-house training are great things) I beat on transparent futures for Ruby. I'm not totally happy with how I detect access for lazy futures, but it does work, if with a bit of magic:
module Futures
class Future
def initialize(func, *args)
@func = func
@args = args
yield self
end
def evaluate
@result = @func.call(self, *@args)
@result.methods.each do |m|
s = <<-EOS
def #{m}(*foos)
@result.send('#{m}', *foos)
end
EOS
instance_eval(s) unless ['instance_eval','__id__','__send__'].member? m
end
self
end
def method_missing(symbol, args)
evaluate unless available?
@result.send(symbol, args)
end
def available?
defined? @result
end
end
LAZY_SKIP_METHODS = ['instance_eval', '__id__', '__send__',
'evaluate', 'available?', '==', '===',
'=~', 'method_missing']
def lazy
Future.new(proc { yield }) do |it|
it.methods.each do |m|
s = <<-EOS
alias __Futures_#{m} #{m}
def #{m}(*foos)
evaluate unless available?
__Futures_#{m}(*foos)
end
EOS
it.instance_eval(s) unless LAZY_SKIP_METHODS.member? m
end
end
end
SPAWN_SKIP_METHODS = ['instance_eval', '__f_thread=', '__id__',
'__send__', 'evaluate', 'available?',
'==', '===', '=~', 'method_missing']
def spawn
f = Future.new(proc { yield }) do |it|
def it.__f_thread=(t)
@thread = t
end
it.methods.each do |m|
s = <<-EOS
alias __Futures_#{m} #{m}
def #{m}(*foos)
@thread.join unless available?
__Futures_#{m}(*foos)
end
EOS
it.instance_eval(s) unless SPAWN_SKIP_METHODS.member? m
end
end
Thread.start do
f.__f_thread=Thread.current
f.evaluate
end
return f
end
end
Note the two Future generating methods, spawn and lazy. Spawn will asynchronously evaluate the block, ~replacing the Future with the result upon completion, and blocking until completion if anything forces evaluation. Lazy will evaluate and replace the future when somethign forces evaluation. Both take a block from which the return value will ~replace the Future upon evaluation. Here's how they're used:
Lazy:
require 'futures.rb'
include Futures
class Wombat
def initialize
puts "initializing a Wombat"
end
def say(x)
# wombats sigh a lot
puts "ahhhh #{x}"
end
end
thing = lazy { Wombat.new }
puts "here"
thing.say "nice"
Will produce the output:
here
initializing a Wombat
ahhhh nice
And the async usage is like:
class SlowWombat < Wombat
def initialize
puts "I am so slow..."
sleep 2
puts "Ah, there I go..."
end
end
other = spawn { SlowWombat.new }
puts "doing something while wombat wakes up..."
puts "gee, this is a slow wombat..."
other.say "uh huh"
Producing:
doing something while wombat wakes up...
I am so slow...
gee, this is a slow wombat...
Ah, there I go...
ahhhh uh huh
With a two second delay (had to run it a few times to get them nicely interspersed though ;-)
In both these examples I have the block instantiate a new object, but there is no need for that, whatever the block returns will ~replace the future when it is evaluated, so remote calls, etc, would be good candidates for async -- if you need the result before it gets back, you'll block on it when you try top get access it.
I have been saying ~replacing because the result of the evaluation isn't really replacing the future -- the future is delegating all calls to result when it becomes available, and doing other things before it becomes available (forcing lazy evaluation, waiting for the evaluation thread to finish). The method redefinition code was amazing fun to write. Maybe I really should learn Lisp macros...
Debugging this kind of absurdly dynamic code is fun, particularly when I forgot to exclude instance_eval from the forwarded methods and couldn't figure out why some methods were just not getting defined on the Future while others were. Oops.
All in all, GREAT fun, and a tool I am going to keep in my belt ;-)
0 writebacks [/src] permanent link
Thu, 06 Jan 2005
Started a new Rails app this evening -- we cannot decide where to register for our wedding, so we're not registering somewhere, we're doing our own registry. Along the way I noticed that there is more than the good old apache.log in the $RAILS_PROJECT/logs. A screenie is the only way to do justice to the pretty nice default logging setup:
This is sort of what using Rails is mostly like. You stumble on a really nice gem—the default logging giving you a breakdown of execution times, translating it to requests per second, giving you any sql, execution times on the sql, etc. Oh yeah, nicely color coding and bolding as well. Then you stumble on another gem. It feels like programming in ruby, where things surprise you by being just really well done, and easier than expected.
Nothing earth shattering, paradigm shifting, etc -- it just works better than expected, consistently.
=)