I am a big fan of the APR versioning guidelines, but there is an element they don't capture well somewhere between major (backwards incompat change) and minor (forward incompat change) in Java. If you follow the, generally recommended practice of exposing things via interfaces (pure virtual classes), you have opened the door for users to implement those interfaces.
In a C-style world, adding a function to a library would bump you from 1.6 to 1.7, using APR guidelines. In an interface-driven Java-style world, adding a method to an interface would bump you from 1.6 to 2.0. Or would it?
To take a concrete example, a coworker (thanks Jax!) recently
re-added first class support for callable statements to jDBI. jDBI
uses a Handle interface to expose operations against a
database. It has gained a method:
public <ReturnType> Call<ReturnType> createCall(String callableSql,
CallableStatementMapper<ReturnType> mapper);
If you implement this interface, the change is backwards
incompatible. An implementation of Handle made against
2.2.2 will not compile against this. On the other hand, the intent
of the library is not for people to implement Handle,
it is to expose the libraries functionality. It is almost a
header file.
So, 2.3 or 3.0?
3 writebacks [/src/java] permanent link
Sat, 10 May 2008
Long Tail Treasure Trove Slides!
Gianugo has posted the slides from our JavaOne presentation, on Slideshare and in pdf form. The talk was awesome to give, we had a killer audience. A huge thank you to all who attended!
2 writebacks [/src/java] permanent link
Wed, 23 Apr 2008
The Shape of Async Callback APIs
When we have async callbacks in a Java API, the idiommatic way of writing the interface to register the callback looks like:
Future<Foo> f = asyncEventThing.addListener(new Listener<Foo>() {
public Foo onEvent(Event e) {
return new Foo(e.getSomethingNifty());
}
})
I'd like to propose that we adopt a new idiom, which is to pass an
Executor along with the listener:
Executor myExecutor = Executors.newSingleThreadExecutor();
// ...
Future<Foo> f = asyncEventThing.addListener(new Listener<Foo>() {
public Foo onEvent(Event e) {
return new Foo(e.getSomethingNifty());
}
}, myExecutor);
The main benefit is that you give the caller control over the threading model for the callback. Right now, most libraries either have a separate thread pool for callbacks, or make the callback on the event generator thread. Usually there is nothing but an obscure reference on a wiki to indicate the behavior.
2 writebacks [/src/java] permanent link
Fri, 07 Dec 2007Thank you Julius Davies! for not-yet-commons-ssl which does exactly what I was looking for
import org.apache.commons.io.IOUtils;
import org.apache.commons.ssl.OpenSSL;
import java.io.File;
import java.io.FileOutputStream;
public class Foo
{
public static void main(String[] args) throws Exception
{
File f = new File("/tmp/foo");
FileOutputStream fout = new FileOutputStream(f);
fout.write(OpenSSL.encrypt("aes256",
"secret".toCharArray(),
"hello world\n".getBytes("UTF-8")));
fout.close();
Process p = Runtime.getRuntime()
.exec("openssl enc -pass pass:secret -d -aes256 -a -in /tmp/foo");
System.out.print(IOUtils.toString(p.getInputStream()));
}
}
Woo hoo!
3 writebacks [/src/java] permanent link
Tue, 11 Sep 2007
Congrats to the "Best Application Server"!
Seam is not only an application server, it is the Best Application Server. Take that JBoss AS, Geronimo, and Glassfish.
1 writebacks [/src/java] permanent link
Wed, 29 Aug 2007
Very Lazy Web: Static Analysis to Detect Blocking Operations
Wouldn't it rock if there was a tool to do static analysis of arbitrary code amenable to static analysis (such as Java) to detect and point out places that will block a thread?
Wouldn't it be double cool if the typical places where there is no choice (say, JDBC) vendors would provide non-blocking extensions?
Almost makes me want to write an async postgresql driver...
/me wonders why the Python community is so far ahead of the Java community on this one.
7 writebacks [/src/java] permanent link
Fri, 24 Aug 2007Russ makes a passing remark regarding Erlang while poking angrily at Java which nails the reason I think most folks are really interested in it.
The reason people are looking at Erlang is not because its beautiful syntax, great documentation, or up-to-date libraries. Trust me. It's because the Erlang VM can run for long periods of time, scaling linearly across cores or processors filling the same niche that Java does right now on the server.
If you are resource constrained (pronounced "hosting providers charge obscene amounts of money for RAM") you don't want to run Java. You really don't want to run Java. It is an operational thing. I have ejabberd running on my personal server and am annoyed at the 13 megs resident it consumes after a month uptime. I could use OpenFire (Diego likes it.) but it sits at 40 megs at startup. Now this isn't apples to apples, they have different feature sets, but it feels about right.
Java has grown to fit the constraints in which the Java Customer Process members like it to be used: running Enterprise Services on fairly beefy hardware. If this is your situation, woot, go forth and win. It is, however, a situation ripe for disruption.
3 writebacks [/src/java] permanent link
Tue, 07 Aug 2007Dan asks, What is the web framework du jour for Java these days? -- it is a good question considering in recent years there has generally been a couple hot tickets. For the most part I agree with his quick comments, but will add a few:
As I commented in Dan's blog, I think we are in a (Java) web framework nuclear winter.
5 writebacks [/src/java] permanent link
Sat, 16 Jun 2007
I was writing something to aggregate a bunch of JMX exports today and was really annoyed at adding environment variables to the test runner. Luckily, Martin pointed me to a fantastic howto on exporting an MBeanServer without supplying env variables to the jvm when it starts up. I specialized what he did a bit to orient it towards testing stuff and wound up with:
package org.skife.test;
import javax.management.MBeanServer;
import javax.management.remote.JMXConnectorServer;
import javax.management.remote.JMXConnectorServerFactory;
import javax.management.remote.JMXServiceURL;
import java.io.IOException;
import java.lang.management.ManagementFactory;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.rmi.registry.LocateRegistry;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* Handy-dandy tool to help with JMX Testing
*/
public class JMXHelper
{
private static int port = -1;
/**
* Ensure JMX is all set up, returns port for JMX RMI Registry
*/
public static int initialize()
{
if (port != -1) return port;
try {
final ServerSocket sock = new ServerSocket();
sock.bind(new InetSocketAddress(0));
port = sock.getLocalPort();
sock.close();
LocateRegistry.createRegistry(port);
MBeanServer mbs = ManagementFactory.getPlatformMBeanServer();
String s = String.format("service:jmx:rmi:///jndi/rmi://:%d/jmxrmi", port);
JMXServiceURL url = new JMXServiceURL(s);
JMXConnectorServer cs =
JMXConnectorServerFactory.newJMXConnectorServer(url, null , mbs);
cs.start();
}
catch (Exception e) {
throw new IllegalStateException("Unable to bind JMX", e);
}
return port;
}
}
Now you can connect to it like normal:
String url = String.format("service:jmx:rmi:///jndi/rmi://localhost:%s/jmxrmi", port);
JMXConnector c = JMXConnectorFactory.connect(new JMXServiceURL(url));
and there is a JMXConnector to your "test" MBeanServer. As with most of JMX, it is kinda werid looking and obscure, but it works well :-)
Update: Martin pointed out that I could use less code. Changed.
0 writebacks [/src/java] permanent link
Wed, 09 May 2007
Long Tail Treasure Trove Slides
I just uploaded an initial export (Powerpoint -> Keynote -> PDF messed some things up) of the slides from Gianugo and my presentation at JavaOne last night, "Long Tail Treasure Trove." Thank you to all the attendees, you were awesome!
If I get a chance, later today, I'll clean up some of the import/export oddities and re-post them!
ps: Henri pointed out a typo in the sample ANTLR grammar, the POSITIONAAL_PARAM production. Sadly, that isn't a typo in the slide. The token name is spelled that way in jDBI... D'oh!
1 writebacks [/src/java] permanent link
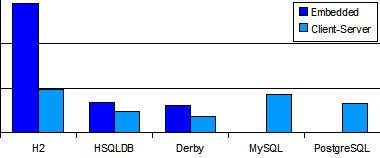
Thu, 26 Apr 2007This needs to be highlighted. Thomas Mueller, the creator of H2, likes to point out the huge performance difference between H2 and other databases. It is extremely important to note that the main driver behind the performance difference is the fact that H2 explicitely forgoes durability. It does not sync data to disk on commit. Bears repeating, H2 does not sync data to disk on commit. You can force it to, in which case the performance hits the same bottleneck every other database hits, disk io:
-- 1024 bytes, 1000 times --
derby: 2192 millis
bdb: 1849 millis
h2: 2221 millis
h2b: 2351 millis
-- 2048 bytes, 1000 times --
derby: 2199 millis
bdb: 2129 millis
h2: 2578 millis
h2b: 2414 millis
The numbers here are running simple inserts and deletes by identity (so that I can include BDB JE). Shockingly, the numbers are all basically the same once you force H2 to sync to disk (executing a "CHECKPOINT SYNC" statement after every DML operation).
H2 is an awesome little database, but if you care about storing your data, please read the fine print where it notes that H2 is not ACID. It is just ACI.
10 writebacks [/src/java] permanent link
Wed, 11 Apr 2007
Guice with Spring Transactions
I futzed a bit with setting up Spring transaction handling in Guice. It was shockingly straightfirward :-)
So, there are several ways to do it, but I did it via having a Module export both a DBI and apply the transaction interceptor. Frankly, I probably wouldn't use this class in a real project because I would just wire it up more specific to how I needed it. However, for the common case of one data source, and annotated transactions. Bingo!
package org.skife.jdbi.v2.unstable.guice;
import com.google.inject.Module;
import com.google.inject.Binder;
import com.google.inject.matcher.Matchers;
import javax.sql.DataSource;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.interceptor.TransactionInterceptor;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.transaction.annotation.AnnotationTransactionAttributeSource;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.skife.jdbi.v2.spring.DBIFactoryBean;
import org.skife.jdbi.v2.IDBI;
public class SpringTransactionalGuiceModule implements Module
{
private final DataSource ds;
public SpringTransactionalGuiceModule(final DataSource ds)
{
this.ds = ds;
}
public void configure(Binder binder)
{
final PlatformTransactionManager ptm = new DataSourceTransactionManager(this.ds);
final DBIFactoryBean bean = new DBIFactoryBean();
bean.setDataSource(ds);
try {
final IDBI dbi = (IDBI) bean.getObject();
binder.bind(IDBI.class).toInstance(dbi);
}
catch (Exception e) {
binder.addError(e);
return;
}
binder.bindInterceptor(Matchers.any(), Matchers.annotatedWith(Transactional.class),
new TransactionInterceptor(ptm, new AnnotationTransactionAttributeSource()));
}
}
This module reuses the jDBI Spring transaction integration glue magic stuff, hence instantiating the DBI instance via the DBIFactoryBean. It then binds Spring's TransactionInterceptor, telling it to base its tx magic on annotations via the AnnotationTransactionAttributeSource and the PlatformTransactionManager.
This could bind the platform transaction manager as well, but for now I don't need it, so I didn't.
To exercise it, I need another module which has my actual things in it, and I need to do something, like:
public static class ThingModule implements Module
{
public void configure(Binder binder)
{
binder.bind(Thing.class);
}
}
public static class Thing
{
private final IDBI dbi;
@Inject
Thing(IDBI dbi)
{
this.dbi = dbi;
}
@Transactional
public void excute(final Callback cb)
{
final Handle handle = DBIUtil.getHandle(dbi);
cb.call(handle);
}
}
public interface Callback
{
public void call(Handle handle);
}
The only transactional element is the Thing#excute method, and it is using the Spring 2.0 @Transactional annotation.
I like to use callbacks for testing transactional stuff like this, reduces the clutter. The only really nasty bit to this, imho, is the Handle handle = DBIUtil.getHandle(dbi); which uses the Spring idiom of having a static helper to get transactionally bound resources. I dislike it, but it is Spring idiom, and I am reusing the jDBI Spring stuff, so... c'est la vie for now.
Setting it up and running, then is just:
public void setUp() throws Exception
{
super.setUp();
this.guice = Guice.createInjector(new ThingModule(),
new SpringTransactionalGuiceModule(Tools.getDataSource()));
}
public void testFoo() throws Exception
{
final Thing thing = guice.getInstance(Thing.class);
assertNotNull(thing);
try {
thing.excute(new Callback()
{
public void call(Handle handle)
{
assertTrue(handle.isInTransaction());
handle.insert("insert into something (id, name) values (?, ?)", 1, "Rob");
throw new IllegalStateException();
}
});
fail("Should have thrown an exception");
}
catch (IllegalStateException e) {
assertTrue(true);
}
final Handle h = openHandle();
assertFalse(h.isInTransaction());
final List<String> names = h.createQuery("select name from something")
.map(StringMapper.FIRST)
.list();
assertEquals(0, names.size());
}
And it all works! Woo hoo!
A drawback, and I haven't found a way around this, is that you cannot provide dependencies to interceptors, so the data source must be available outside the injector. Bob says it will be in the next release though, so woot!
4 writebacks [/src/java] permanent link
Sat, 24 Mar 2007I've been playing with Guice, and to repeat myself, Bob and Kevin know how to write a clean client API, that is for sure :-) In terms of IoC/DI/Flooflah I think Guice has finally knocked Pico out for elegance. Spring does DI, and is fantastic as a library, but I have never liked its dependency resolution options and how it functions container-wise.
Looking at Guice I did run into the thing most folks latched on to immediately, it has no lifecycle hooks! Egads, how shall we live! This actually matters as almost everything I do, lately, is multithreaded and embarrassingly concurrent, though. Because of the oddities of the Java Memory Model, simple lifecycle hooks are awfully useful -- just a start/stop is enough, really. You can work around it by having bootstrapping classes, but... yuck. Anyway, I digress.
Then the obviousness of it smacks me upside my head -- lifecycle crap is orthogonal to dependency resolution, we have just gotten used to seeing them bundled together. So I started futzing with non-sucky ways to do lifecycles outside the container.
Lifecycle events are just events, and despite the trend away from it, I think first-class events trump implicit events. This means you pass the event to an event listener rather than have a no-arg method invoked. Heresy, probably, but oh well. So what is an event? Well, crap, really there is no reason to restrict it, so an event is any Java object.
Java's lack of closure support makes for craploads of one-method interfaces as event listeners. This is idiommatic, and frequently idiommatic is good as it reduces the number of concepts you have to understand to learn something new, but I always find it annoying. Spring and other containers have been pushing folks towards having the classes which would register lifecycle listeners just be the listener (via the no-arg method), so that heresy has already gained some traction. Bah, go with it. We can dispatch events based on annotating a method as an event listener and use the argument type to match which events it cares about. So, stab #1:
public class EventBus
{
private final List<Object> listeners = new CopyOnWriteArrayList<Object>();
public void register(Object listener)
{
listeners.add(listener);
}
public void fire(Object event) throws IllegalAccessException,
InvocationTargetException
{
for (final Object listener : listeners) {
for (final Method m : listener.getClass().getMethods()) {
if (m.getAnnotation(EventListener.class) != null) {
final Class[] params = m.getParameterTypes();
if (params.length == 1 && params[0].isAssignableFrom(event.getClass())) {
m.invoke(listener, event);
}
}
}
}
}
}
This is extremely inefficient, but it is a couple minutes of hacking. It is also easy to optimize by analyzing listeners when they are registered instead of when the event is fired. That also allows for detecting illegally shaped listener methods at registration time, instead of just ignoring them, blah blah blah. Regardless, it works for now. Our thing which wants to receive events looks like:
public class RockingChair
{
private final List<String> events = new ArrayList<String>();
@EventListener
public void startRocking(Start event)
{
events.add("start");
}
@EventListener
public void fallOver(Stop event)
{
events.add("stop");
}
public List<String> getEvents() {
return Collections.unmodifiableList(events);
}
}
So here we have event methods on a listener class, and support arbitrary events. Driving it just looks something like this.
public void testBasics() throws Exception
{
EventBus bus = new EventBus();
RockingChair chair = new RockingChair();
bus.register(chair);
Start event = new Start();
bus.fire(event);
assertTrue(chair.getEvents().contains("start"));
}
public void testSubclass() throws Exception
{
EventBus bus = new EventBus();
RockingChair chair = new RockingChair();
bus.register(chair);
Start event = new Start() {};
bus.fire(event);
assertTrue(chair.getEvents().contains("start"));
}
Nothing fancy here, and it works fairly well. You can add lots of shiny knobs if you want to, but how do we go about hooking it into Guice? The obvious way is just to add the EventBus as a component and make things which depend on lifecycle events dependent upon it:
public class Glider
{
private final List<String> events = new CopyOnWriteArrayList<String>();
@Inject
public Glider(EventBus bus)
{
bus.register(this);
}
@EventListener
public void rock(Start event)
{
events.add("start");
}
@EventListener
public void fallOver(Stop event)
{
events.add("stop");
}
public List<String> getEvents()
{
return Collections.unmodifiableList(events);
}
}
This bothers me though. I do like passing an event listener to the bus other than the Glider itself, it seems to be polluting the heck out of the Glider's API to have those event listener methods we refactor it just a touch:
public class Glider
{
private final List<String> events = new CopyOnWriteArrayList<String>();
@Inject
public Glider(EventBus bus)
{
bus.register(new Object()
{
@EventListener
public void rock(Start event)
{
events.add("start");
}
@EventListener
public void fallOver(Stop event)
{
events.add("stop");
}
});
}
public List<String> getEvents()
{
return Collections.unmodifiableList(events);
}
}
By flagging the method as an EventListener and dispatching based on parameter type we can now have pretty painless multiple-event listener instances. If you could have an anonymous inner class implement more than one interface you could accomplish the same with interface based listeners. Hmm, you could also hide that behind a library where you do something like:
bus.registerInterfaceBasedListener(new Object() {
public void onFoo() {}
publc void onBar() {}
}, BarListener.class, FooListener.class);
But you are then dispatching on instanceof which isn't any prettier and is not really more optimizable. Need to think on it a bit more :-)
Regardless, I rather like argument-type based dispatch of events from an event bus which accepts arbitrary instances as events, and it does play pretty nicely with Guice, or anything else. Much more mucking to consider, I think :-)
2 writebacks [/src/java] permanent link
Wed, 14 Feb 2007[rant]
And we get JSR-311 because "Correct implementation requires a high level of HTTP knowledge on the developer's part." (pointed out by Dan and Dave) This is where we have reasonably good developers trying to design software for presumed-incompetent developers which will in fact be used unhappily by basically competent developers.
Contrast this to other tools such as IDEA which made the shocking assumption that programmers were smart and knew how to program, or to Rails which has been designed and written by good developers for use by... themselves.
[/rant]
That is actually an interesting idea. I know of only a couple developer-targeted projects which have been smashing successes where the goal has been "easy enough for not-very-good developers to be productive with." Those are things like PHP and VB. In the PHP case I know of a lot of heated discussions about features to include and exclude, such as purposefully resisting namespaces. It seems like a stupid thing to choose to do, but when large numbers of your users think in terms of dynamic web pages, not applications, it matters.
On the other hand most of the successful, technically and popularly, open source projects I can think of were designed specifically for use by the people writing the software where others have been welcome to use that software as well.
0 writebacks [/src/java] permanent link
Thu, 28 Dec 2006Just added Spring (2.0) support back into jDBI (2.0). When I started I looked back at the 1.4 codebase to see what I had done in the previous version... The 2.0 is much smaller, lighter, and has less special stuff. Yea!
This has been my first chance to work with Spring 2.0 and I rather like it. The SPI for playing with the transaction manager is pretty much identical, which is cool. The @Transactional annotation stuff works very nicely. I also learned, along the way, that Derby supports nested transactions. Sweet!
Anyway, jDBI has come a helluva long way in two years. The 2.0 codebase is getting the kinks worked out and I really like it.
Anywho, jDBI 2.0pre13 has been cut. I am trusting the codebase, so hopefully will hit a 2.0 final soon. In prerelease form it trumps 1.4.X right now, but I don't want to rule out API tweaks until I've used it anger a bit more.
0 writebacks [/src/java/jdbi] permanent link
Tue, 28 Nov 2006
Oracle's DML Returning and jDBI 2.0pre7
So I broke down and have started adding some database-specific functionality to jDBI. The first bit is a statement customizer which does the downcasts and whatnot to make it convenient to use oracle's dml returning stuff (like "insert into something (id, name) values (something_id_seq.nextval, ?) returning id into ?").
public void testFoo() throws Exception
{
Handle h = dbi.open();
OracleReturning<Integer> or = new OracleReturning<Integer>(new ResultSetMapper<Integer>() {
public Integer map(int index, ResultSet r) throws SQLException
{
return r.getInt(1);
}
});
or.registerReturnParam(1, OracleTypes.INTEGER);
h.createStatement("insert into something (id, name) values (17, 'Brian') returning id into ?")
.addStatementCustomizer(or)
.execute();
List<Integer> ids = or.getReturnedResults();
assertEquals(1, ids.size());
assertEquals(Integer.valueOf(17), ids.get(0));
h.close();
}
This allows for a nice API, without client code downcasts as well, to make use of results returned from DML against Oracle. When I get a chance I'll add one for Postgres as well :-) The code to do it is pretty straightforward. The nice part was that it required no changes to the core of jDBI 2.0 to do this :-)
Pushed 2.0pre7 as well ;-) Have fun!!
0 writebacks [/src/java/jdbi] permanent link
Wed, 15 Nov 2006So, trying to reproduce a timing issue in ActiveMQ failover (which Hiram seems to have fixed in the recent 4.0.2 release, thank you!) I was able to whip various clients together super-quick:
#!/usr/bin/env jruby
require 'java'
module AMQFailoverTest
include_package "org.apache.activemq"
include_class "javax.jms.Session"
b = "failover://(tcp://golem:35000,tcp://golem:35001)"
factory = ActiveMQConnectionFactory.new b
connection = factory.createConnection();
session = connection.createSession(false, Session::AUTO_ACKNOWLEDGE)
producer = session.createProducer(session.createTopic("test"))
loop do
producer.send(session.createTextMessage("this is only a test"))
end
end
Thank you, JRuby folks! :-)
0 writebacks [/src/java] permanent link
Thu, 28 Sep 2006Yea! Was just (finally) poking through the changes in the upcoming Spring 2.0 release and ran across their bean scopes. I've wanted this for a long time. Glad to see it arriving!
3 writebacks [/src/java] permanent link
Sat, 23 Sep 2006I had the opportunity, recently, to play with Grizzly and more specifically, their ARP . Along the way Jean-Francois Arcand was kind enough to give me enough pointers for something ~workable to emerge! Thank you!
Step one looked like:
package org.skife.grizzly;
import com.sun.enterprise.web.connector.grizzly.SelectorThread;
import java.io.IOException;
public class App
{
public static void main(String[] args) throws IOException,
InstantiationException
{
SelectorThread sel = new SelectorThread();
sel.setPort(8000);
// XXX
sel.setDisplayConfiguration(true);
sel.initEndpoint();
sel.startEndpoint();
}
}
Where I had no clue what to do in XXX. This sets up and starts the basic server, but it doesn't actually do anything (except accept connections). What I wanted was something like this:
def handle(request, responder)
instructions = extractInstructions(request)
LongRunningThing.submit(instructions, lambda(arg) {
responder.submit(lambda(response) {
response.write(arg.responseBody)
response.complete()
})
});
end
The next step, then was to add the async processing filter. This is a filter on the execution chain not on the HTTP stream (such as servlet filters are). The code becomes:
public static void main(String[] args) throws IOException, InstantiationException
{
SelectorThread sel = new SelectorThread();
sel.setPort(8000);
sel.setEnableAsyncExecution(true);
AsyncHandler handler = new DefaultAsyncHandler();
handler.addAsyncFilter(new AsyncFilter()
{
public boolean doFilter(AsyncExecutor executor)
{
return false;
}
});
sel.setAsyncHandler(handler);
sel.setDisplayConfiguration(true);
sel.initEndpoint();
sel.startEndpoint();
}
And I am stuck again :-) The AsyncFilter is passed the HTTP processing state, and a handle to the network event handling dodad. To do anything useful, we need to grab the next step in the chain and, er, delay it a bit. Our filter becomes:
handler.addAsyncFilter(new AsyncFilter()
{
public boolean doFilter(final AsyncExecutor executor)
{
final AsyncTask asyncTask = executor.getAsyncTask();
final AsyncHandler asyncHandler = executor.getAsyncHandler();
final DefaultProcessorTask processorTask =
(DefaultProcessorTask) executor.getAsyncTask().getProcessorTask();
processorTask.getRequest().setAttribute(CALLBACK_KEY, new Runnable() {
public void run()
{
asyncHandler.handle(asyncTask);
}
});
processorTask.invokeAdapter();
return false;
}
});
Phew, a chunk of confusing code in there. I'll attempt to explain my understanding of it, and hope Jean-Francois will correct my glaring mistakes. He gave me the snippet that is the basis for this, and I don't full get it (not having fully driven through Grizzly's innards (yet)).
AsyncTask from the AsyncExecutor. This represents, I think, the next step in the chain. We hold onto that, we'll use it in just a moment.
AsyncHandler. Not sure the details of this, but it seems to control the processing of the async tasks that make up the request processing life cycle. We'll be using this with the AsyncTask.
ProcessorTask. This is the thing that is responsible for processing this specific request. From it we can obtain (and we do) the Request instance we are intercepting the processing chain of.
Runnable in this case, just submits the AsyncTask we have obtained back for further execution. When this callback is invoked, the request processing will pick back up based on whatever scheduling algorithm is in use (just a queue, I believe). We store the callback on the request so that it will be available to our handler.
Adaptor for this processor task/request. The adaptor is, in a typical situation, the servlet container. In this case it is a custom adaptor as I didn't muck with a servlet container here. That would make it all more complicated because of servlet's unfortunate contract about committing responses when Servlet#service returns. I digress.
false from the filter to indicate that the process chain should not continue normally -- we signal that we are going to take care of things. Woot!
Okay, so we have stopped the normal HTTP processing chain for this request, an created a function that will let us resume it when we want to. Sweet! Now we need an Adapter so that we can actually do something with the response. We use a silly little adapter, like this:
private static class MyAdapter implements Adapter
{
static byte[] CONTENT;
{
CONTENT = ByteChunk.convertToBytes("hello world!\n");
}
private static final ScheduledExecutorService exec =
Executors.newScheduledThreadPool(2);
public void service(final Request req, final Response res)
throws Exception
{
exec.schedule(new Callable<Void>() {
public Void call() throws Exception
{
res.setStatus(200);
byte[] bytes = CONTENT;
ByteChunk chunk = new ByteChunk();
res.setContentLength(bytes.length);
res.setContentType("text/plain");
chunk.append(bytes, 0, bytes.length);
res.doWrite(chunk);
Runnable completion =
(Runnable) req.getAttribute(CALLBACK_KEY);
completion.run();
return null;
}
}, 10, TimeUnit.SECONDS);
}
public void afterService(Request req, Response res) throws Exception
{
req.action(ActionCode.ACTION_POST_REQUEST , null);
}
public void fireAdapterEvent(String type, Object data)
{
}
}
Now, this is a Coyote Adapter, Tomcat style. In our adapter we do something fun, we immediately schedule a Callable to be invoked 10 seconds later! This just simulates some slow asynchronous process going on. The service method schedules this and returns. It will return back to our filter, via a couple intermediary returns, where the filter returns false to indicate that we are going to restart things later, when we feel like it.
Okay, so ten seconds later we set up our response with a chunk of bytes. I am assured that writing to the Response object at this point is okay. I want to dig in and see if I can get it to do chunked responses from here so as to be able to stream and lower the memory footprint, but that is for later. For now we just fire a small response. After setting up the response we pull the callback out of the request and invoke it.
Invoking the callback submits the async task we had earlier grabbed to be finished, and the response gets shoved down the wire at the next opportunity. Cool!
The final form looks like this:
package org.skife.grizzly;
import com.sun.enterprise.web.connector.grizzly.*;
import com.sun.enterprise.web.connector.grizzly.async.DefaultAsyncHandler;
import org.apache.coyote.Adapter;
import org.apache.coyote.Request;
import org.apache.coyote.Response;
import org.apache.coyote.ActionCode;
import org.apache.tomcat.util.buf.ByteChunk;
import java.io.IOException;
import java.util.concurrent.Callable;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class App
{
private static final String CALLBACK_KEY = "org.skife.grizzly.FINISH_REQUEST";
public static void main(String[] args) throws IOException, InstantiationException
{
SelectorThread sel = new SelectorThread();
sel.setPort(8000);
sel.setAdapter(new MyAdapter());
final AsyncHandler handler = new DefaultAsyncHandler();
handler.addAsyncFilter(new AsyncFilter()
{
public boolean doFilter(final AsyncExecutor executor)
{
final AsyncTask asyncTask = executor.getAsyncTask();
final AsyncHandler asyncHandler = executor.getAsyncHandler();
final DefaultProcessorTask processorTask =
(DefaultProcessorTask) executor.getAsyncTask().getProcessorTask();
processorTask.getRequest().setAttribute(CALLBACK_KEY, new Runnable() {
public void run()
{
asyncHandler.handle(asyncTask);
}
});
processorTask.invokeAdapter();
return false;
}
});
sel.setAsyncHandler(handler);
sel.setEnableAsyncExecution(true);
sel.setDisplayConfiguration(true);
sel.initEndpoint();
sel.startEndpoint();
}
private static class MyAdapter implements Adapter
{
static byte[] CONTENT;
{
CONTENT = ByteChunk.convertToBytes("hello world!\n");
}
private static final ScheduledExecutorService exec =
Executors.newScheduledThreadPool(2);
public void service(final Request req, final Response res)
throws Exception
{
exec.schedule(new Callable<Void>() {
public Void call() throws Exception
{
res.setStatus(200);
byte[] bytes = CONTENT;
ByteChunk chunk = new ByteChunk();
res.setContentLength(bytes.length);
res.setContentType("text/plain");
chunk.append(bytes, 0, bytes.length);
res.doWrite(chunk);
Runnable completion =
(Runnable) req.getAttribute(CALLBACK_KEY);
completion.run();
return null;
}
}, 10, TimeUnit.SECONDS);
}
public void afterService(Request req, Response res) throws Exception
{
req.action( ActionCode.ACTION_POST_REQUEST , null);
}
public void fireAdapterEvent(String type, Object data)
{
}
}
}
It doesn't do a lot, but does demonstrate how it works, or at least a start at how it works. There are a number of things I'm not sure of yet, such as the reason for the specific Adapter#afterService setup (Jean-Francois said to do it, I haven't yet dug into why, though). Fun start, though!
3 writebacks [/src/java] permanent link
Thu, 07 Sep 2006I've been mucking with Dojo widgets a lot lately, and in writing a new base widget (for doing inplace widget creation using existing annotated dom nodes rather than templates) I finally ground my teeth against browser-refresh based testing enough to do something. I was stupid, automated testing of dojo widgets is easy!
Take this example:
dojo.hostenv.setModulePrefix("skife", "/dojo-stuff/skife");
dojo.require("skife.test");
dojo.require("skife.widget.InplaceWidget");
var create = function(s) {
var node = document.createElement("div");
node.innerHTML = s;
var parser = new dojo.xml.Parse();
var frag = parser.parseElement(node, null, true);
dojo.widget.getParser().createSubComponents(frag);
return node;
}
skife.test.suite("Testing org.skife.InplaceWidget", function(s) {
s.test("Widget is instantiated declaratively", function(t) {
var called = false;
dojo.widget.defineWidget("skife.test.DummyWidget1", skife.widget.InplaceWidget, {
postAttachDom: function() {
called = true;
}
});
var div = create("<div dojoType='DummyWidget1'></div>");
t.assert("postAttachDom was not called", called)
});
s.test("In place nodes are attached", function(t) {
dojo.widget.defineWidget("skife.test.DummyWidget2", skife.widget.InplaceWidget, {
postAttachDom: function() {
t.assertNotNull("hi node not attached", this.hi)
}
});
var div = create("<div dojoType='DummyWidget2'>" +
"<span dojoAttachPoint='hi'>Hi</span></div>");
});
})
In this case I need to use declarative widget creation, so the hardest part was figuring out how to get the parser to run over the dom tree I had just made. The Dojo FAQ had two (different) ways of doing it, neither of which work anymore. Luckily the kindly folks in #dojo pointed me to ContentPane which does this (see the create function earlier).
Anyway, this served as a good reminder to me that not testing because you think something will be hard to test is stupid. Once you try and prove it is hard to test, then you have some legs to make excuses on, until then, kick yourself in the ass and go test some more :-)
Along the way I started cleaning up the JS test harness (re-namespaced into something less likely to have collisions!) I've been mucking with. I've been n the insane side of busy lately so pretty much everything not directly involved with $goal had fallen by the wayside for a bit. Fun to have some breathing room to pick things up!
{kind=link}