Brian's Waste of Time
Shedding is a technique Paul, John, and I hashed out (during the recent ApacheCon hackathon) for service lookup in pure HTTP. The problem it tries to solve is resolving where to make a request to if you have a URL, say http://storage.service/session which is a backend service for managing session state in Hypothetical Incorporated.
With shedding you set up DNS to send all traffic on the .service. domain to a set of shed servers. The shed servers serve up HTTP and respond to all requests with a 302 to the correct location, so our request above would look like:
--- Request --- --- Response ---
POST /session HTTP/1.1
Host: storage.service
Content-Length: 0
HTTP/1.x 302 Moved
Location: http://10.0.1.5/session
POST /session HTTP/1.1
Host: 10.0.1.5
Content-length: 0
HTTP/1.x 201 Created
Location: http://storage.service/1234
Content-length: 0
The shed server basically "sheds" the requests off to other servers. Now, creating this session storage required an extra request to hit the shed server. Ick. We can narrow the definition of the 302 response for internal services though to apply to just the host moving, though. This feels kind of dirty at first, but it gives us a very interesting benefit when combined with long-lived HTTP connections (the kind you use for internal services) -- you can maintain a pool of connections for a hostname obtained from following the redirect chain.
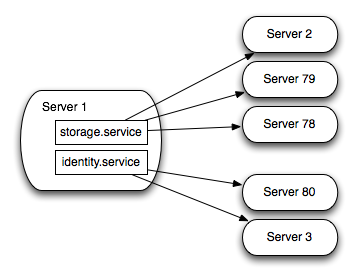
As you accumulate connections you wind up building a pool attached to the different servers that the sheds redirect you to. The shed behavior knowledge becomes built into the connection pool rather than the client. The client just asks for a connection to storage.service and it gets one that points to something capable of servicing it. If there is no connection available it can create a new one.
So, given a client which knows about the narrowed definition of 302, you pay no penalty, for a client which does not you make an extra request but get correct behavior. Even for the client which doesn't know about the sheds, they should be maintaining long lived connections to both the shed server and to the service instance, so you at least avoid the handshakes. Not shabby.
So, that is the client view, let's see the shed view. For resiliency the sheds should be allocated in replicated clusters, probably using an eventual-consistency mechanism for maintaining their knowledge of the state of the world. I suspect that a fast-read version of a paxos database between them, where reads can be executed against any node and do not get serialized into the state machine, but only get the view as that instance sees it, would work fine in practice. Or not, I am tired and this is irrelevant to shedding itself :-)
So the group of shed servers would serve a set of servers arranged into a tree of sheds, as in this logical diagram. The bottom level sheds, [A B C] and [X Y Z] we'll call Line Sheds. The top tier ones, [M N O] we'll call Master Sheds.
The servers serviced by a set of sheds need to announce their availability to the sheds somehow. Various mechanisms can be used, for now it is irrelevant. The line sheds learn about the services using those line sheds. The line sheds will direct traffic between those instances, providing good locality of service in the common case.
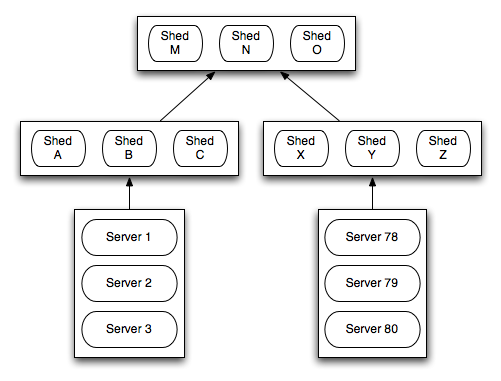
If a line shed doesn't know about any instances of a service it punts up to the master sheds via a 302. The master sheds then 302 to a different set of line sheds. An example, following our logical diagram with a request originating from Server 1 sent to Shed A
--- Request --- --- Response ---
POST /session HTTP/1.1
Host: storage.service
Content-Length: 0
X-Comment: To Shed A
HTTP/1.x 302 Moved
Location: http://[shed m]/session
X-Comment: From Shed A
POST /session HTTP/1.1
Host: [shed m]
Content-length: 0
HTTP/1.x 302 Moved
Location: http://[shed y]/session
X-Comment: From Shed M
POST /session HTTP/1.1
Host: [shed y]
Content-length: 0
HTTP/1.x 302 Moved
Location: http://[server 79]/session
X-Comment: From Shed Y
POST /session HTTP/1.1
Host: [server 79]
Content-length: 0
HTTP/1.x 201 Created
Location: http://storage.service/1234
Content-length: 0
X-Comment: From Server 79
This redirect chain is obviously not ideal, but it will only be followed once (per connection establishment), after that the connection will be pooled and subsequent requests to storage.service will hit Server 79 directly.
To handle this, line sheds need to tell the master sheds each service type they know about so that the master sheds can properly send delegated redirects. The protocol needs to ensure that a "I have no more X" message has made it to masters BEFORE a delegated redirect is sent up or it may be delegated back to the one delegating!
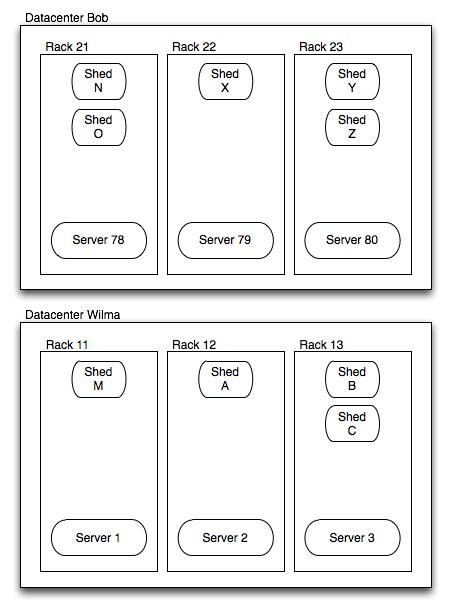
To put this scenario in useful context, consider the following physical layout to correspond to the logical one used this far. We have two datacenters and we want to service requests in the same one, if possible, but fail over to the remote if need be. We distribute the line sheds between racks in each datacenter, and distribute the master sheds between datacenters.
But wait, hasn't this problem been solved? Let's revisit the parameters. We want to solve this for internal services, not for the web. We want to take advantage of service locality (pick service instances nearest the source of the request). We want to be able to very rapidly add and remove instances of a service. We want to, as rapidly as possible stop routing requests to dead instances. Finally, we want to minimize load on the network in general.
The first obvious answer is to just use DNS like Paul intended. Sadly, DNS kind of sucks for this when you have a changing service landscape. TTLs less than a minute tend to be ignored so a dead instance will be in rotation up to a minute, new instances will only be picked up after a minute. Using a one minute TTL leads to a lot of extra traffic in the steady state case. The only "load balancing" facility (without going into a custom DNS client which consumers SRV records) is straight round-robin. Clients have differing behaviors with regards to round-robin DNS to top it off. You can get locality by only advertising local services, but then if the local services go tits up, you don't make use of more remote services. Basically, DNS can be made to work, but not as well as I want.
Okay, how about pointing DNS at a load balancer? This works pretty well. The load balancer then becomes your bandwidth limiting factor and bandwidth through a load balancer is way pricier than through a switch. That said, if you have deep pockets, score!
Fine, how about using a directory server instead of DNS? This would be the Orthodox Java Way (JNDI), the Orthodox Microsoft Way (AD), and most directory/LDAP implementations update really quickly, are very read optimized, etc, etc. You lose use of your URLs though. This is fine in an RPC/CORBA/RMI/Thrift world, sucks if you are in HTTP land though.
Given the constraints outlined, I think shedding has some merit. Feedback, particularly on why this could never work, is extremely appreciated!